IPC:进程间通信详解
从管道、消息队列到共享内存、Socket 与 RPC,系统性梳理进程间通信(IPC)的核心实现方式、原理与选型。
一、IPC 是什么?#
IPC(Inter-Process Communication,进程间通信) 指:同一台机器上(也可以是不同机器上)不同进程之间,为了交换数据、同步状态而使用的一系列机制。
因为每个进程有独立的虚拟地址空间,不能像函数那样直接调用彼此的变量,所以需要操作系统提供“桥梁”——这就是 IPC。
二、常见的 IPC 实现方式 & 原理#
下面以类 Unix / Linux 为例,Windows 也有类似概念。
1. 管道(pipe / FIFO)#
- 特点:单向或半双工、面向字节流、父子进程之间使用很方便。
- 实现原理:
- 内核中维护一个环形缓冲区;
- 写进程往缓冲区写数据,读进程从缓冲区读数据;
- 内核负责阻塞/唤醒读写进程(没有数据时读阻塞、缓冲区满时写阻塞)。
- 命名管道(FIFO):有路径名,可以在非亲缘关系进程之间使用。
适合:简单的“流水线”式生产者-消费者。
示例:C 语言匿名管道(父写子读)
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
int main(void) {
int fds[2];
pipe(fds);
if (fork() == 0) { // child
close(fds[1]);
char buf[64] = {0};
read(fds[0], buf, sizeof(buf));
printf("child got: %s\n", buf);
_exit(0);
}
close(fds[0]);
const char *msg = "hello from parent";
write(fds[1], msg, strlen(msg) + 1);
close(fds[1]);
wait(NULL);
}2. 消息队列(Message Queue)#
- 特点:按消息为单位(有消息边界),支持优先级。
- 实现原理:
- 内核里维护一个“队列对象”;
- 每条消息有类型 / 优先级,写入队列尾部或插队;
- 读进程按类型/优先级取出消息;
- 内核负责同步、阻塞、唤醒。
- 对比管道:
- 管道是“没有边界的字节流”,消息队列是“有边界的离散消息”。
适合:多生产者-多消费者、逻辑清晰、需要按消息处理的场景。
示例:System V 消息队列(C 语言)
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <string.h>
struct msgbuf {
long mtype;
char text[64];
};
int main(void) {
key_t key = ftok(".", 'q');
int mqid = msgget(key, IPC_CREAT | 0666);
if (fork() == 0) { // consumer
struct msgbuf msg;
msgrcv(mqid, &msg, sizeof(msg.text), 1, 0);
printf("worker: %s\n", msg.text);
} else {
struct msgbuf msg = {.mtype = 1};
strcpy(msg.text, "build finished");
msgsnd(mqid, &msg, sizeof(msg.text), 0);
wait(NULL);
msgctl(mqid, IPC_RMID, NULL);
}
}3. 共享内存(Shared Memory)#
- 特点:最快的 IPC;双方直接访问同一块内存。
- 实现原理:
- 内核分配一块物理内存;
- 把这块物理内存映射到多个进程的虚拟地址空间;
- 之后进程可以像访问自己内存一样读写这块区域。
- 问题:没有自动同步,需要自己配合锁 / 信号量 / 自旋锁 / 条件变量等保证互斥和可见性。
适合:数据量很大、频繁读写、性能敏感的场景(例如多进程共享缓存)。
示例:POSIX 共享内存 + memcpy
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <unistd.h>
#include <string.h>
int main(void) {
const char *name = "/ipc_shm";
int fd = shm_open(name, O_CREAT | O_RDWR, 0666);
ftruncate(fd, 4096);
void *addr = mmap(NULL, 4096, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (fork() == 0) {
char buf[32];
memcpy(buf, addr, sizeof(buf));
printf("child read: %s\n", buf);
} else {
memcpy(addr, "shared data", 12);
wait(NULL);
munmap(addr, 4096);
shm_unlink(name);
}
}4. 信号量(Semaphore)& 互斥锁(Mutex)#
严格说是同步机制,但经常和 IPC 绑定在一起用:
- 信号量:整数计数 + 原子加减,控制可同时进入临界区的进程数。
- 互斥锁:信号量的一种特殊情况(最大值 = 1),保证同一时间只有一个执行者。
通常搭配共享内存,做“数据共享 + 同步保护”。
示例:POSIX 命名信号量保护临界区
#include <fcntl.h>
#include <semaphore.h>
#include <stdio.h>
#include <unistd.h>
int main(void) {
sem_t *sem = sem_open("/ipc_sem", O_CREAT, 0644, 1);
if (fork() == 0) {
sem_wait(sem);
puts("child enters critical section");
sem_post(sem);
} else {
sem_wait(sem);
puts("parent enters critical section");
sem_post(sem);
wait(NULL);
sem_unlink("/ipc_sem");
}
}5. 信号(Signal)#
- 特点:非常轻量的“异步通知机制”。
- 实现原理:
- 内核给目标进程设置一个“信号标记”;
- 进程在合适的时机(中断返回、系统调用返回)检查并调用对应的信号处理函数。
- 适合:
- 通知进程“发生了某件事”(如 SIGINT、SIGTERM、SIGCHLD 等);
- 不适合传输大数据,只传一点状态/编号。
示例:Python 信号通知
import os
import signal
import time
def handle(sig, frame):
print(f"parent got signal {sig}")
signal.signal(signal.SIGUSR1, handle)
if os.fork() == 0:
time.sleep(1)
os.kill(os.getppid(), signal.SIGUSR1)
else:
signal.pause() # 阻塞等待信号6. 套接字(Socket)#
- 本地 IPC 套接字(Unix Domain Socket):
- 仍然是“socket”接口(
bind/listen/accept/connect/send/recv),但不走网络协议栈; - 数据只在本机内核空间中传递,效率比 TCP/UDP 高。
- 仍然是“socket”接口(
- 网络套接字则可以跨机器,是 “IPC + 网络” 的混合形式。
适合:
- 多进程服务器(例如 Nginx、PostgreSQL 的进程间通信);
- 希望以后方便迁移到分布式(跨机器)的场景。
真实案例:Nginx worker 进程通信
Nginx 使用 Unix Socket 作为 FastCGI / uWSGI 后端的通信方式:
View Code
# nginx.conf - 通过 Unix Socket 连接 PHP-FPM
upstream php_backend {
# 使用 Unix Socket 而不是 TCP,性能更高
server unix:/var/run/php/php8.1-fpm.sock;
}
server {
location ~ \.php$ {
fastcgi_pass php_backend;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}对应的 PHP-FPM 配置:
; /etc/php/8.1/fpm/pool.d/www.conf
[www]
; 监听 Unix Socket 而不是 TCP 端口
listen = /var/run/php/php8.1-fpm.sock
listen.owner = www-data
listen.group = www-data
listen.mode = 0660为什么用 Unix Socket? 同一台机器上,Unix Socket 比 TCP 127.0.0.1:9000 快 ~10-30%,因为跳过了 TCP/IP 协议栈。
示例:Python Unix Domain Socket echo
import os
import socket
import threading
SOCK_PATH = "/tmp/ipc.sock"
def serve():
if os.path.exists(SOCK_PATH):
os.remove(SOCK_PATH)
with socket.socket(socket.AF_UNIX, socket.SOCK_STREAM) as server:
server.bind(SOCK_PATH)
server.listen()
conn, _ = server.accept()
with conn:
data = conn.recv(1024)
conn.sendall(data.upper())
threading.Thread(target=serve, daemon=True).start()
with socket.socket(socket.AF_UNIX, socket.SOCK_STREAM) as client:
client.connect(SOCK_PATH)
client.sendall(b"ping from client")
print(client.recv(1024))7. RPC / gRPC / D-Bus 等“高级 IPC”#
这些通常是在底层 IPC(如 socket 或管道)之上再封一层协议:
- 自动帮你做:
- 序列化 / 反序列化;
- 请求-响应匹配;
- 服务发现、重试、超时等。
- 本质:函数调用的体验 + IPC 的实现。
Linux 桌面上的 D-Bus、Android 的 Binder 都是典型的“增强型 IPC 框架”。
真实案例:D-Bus 系统服务调用
D-Bus 是 Linux 桌面的标准 IPC 机制,底层用 Unix Socket 实现:
# Python 调用系统 D-Bus 服务(查询网络状态)
import dbus
# 连接到系统总线(/var/run/dbus/system_bus_socket)
bus = dbus.SystemBus()
# 获取 NetworkManager 服务的代理对象
nm = bus.get_object(
'org.freedesktop.NetworkManager', # 服务名(类似 IP 地址)
'/org/freedesktop/NetworkManager' # 对象路径(类似端口)
)
# 获取接口并调用方法
props = dbus.Interface(nm, 'org.freedesktop.DBus.Properties')
state = props.Get('org.freedesktop.NetworkManager', 'State')
print(f"NetworkManager state: {state}") # 70 = connected
# D-Bus 底层:
# 1. 序列化方法调用为 D-Bus 消息格式
# 2. 通过 Unix Socket 发送到 dbus-daemon
# 3. dbus-daemon 路由到 NetworkManager 进程
# 4. 返回结果通过相同路径返回Android Binder 的简化示意
// Android 跨进程调用示例(AIDL 生成的代码简化版)
// 客户端进程
IMyService service = IMyService.Stub.asInterface(
ServiceManager.getService("my_service") // 通过 Binder 驱动查找服务
);
// 这行代码实际会:
// 1. 序列化参数到 Parcel
// 2. 通过 /dev/binder 设备文件发送到内核
// 3. 内核将数据拷贝到服务端进程
// 4. 服务端反序列化并执行
// 5. 结果原路返回
String result = service.doSomething("hello"); // 看起来像本地调用Binder vs 传统 IPC:Binder 只需要一次数据拷贝(通过 mmap),而传统 Socket 需要两次(用户态→内核→用户态)。
示例:Python XML-RPC(RPC 的轻量形态)
from xmlrpc.server import SimpleXMLRPCServer
import threading
import xmlrpc.client
def add(x, y):
return x + y
server = SimpleXMLRPCServer(("127.0.0.1", 9000), logRequests=False)
server.register_function(add, "add")
threading.Thread(target=server.serve_forever, daemon=True).start()
proxy = xmlrpc.client.ServerProxy("http://127.0.0.1:9000")
print("result:", proxy.add(40, 2))三、IPC 的核心原理(抽象一下)#
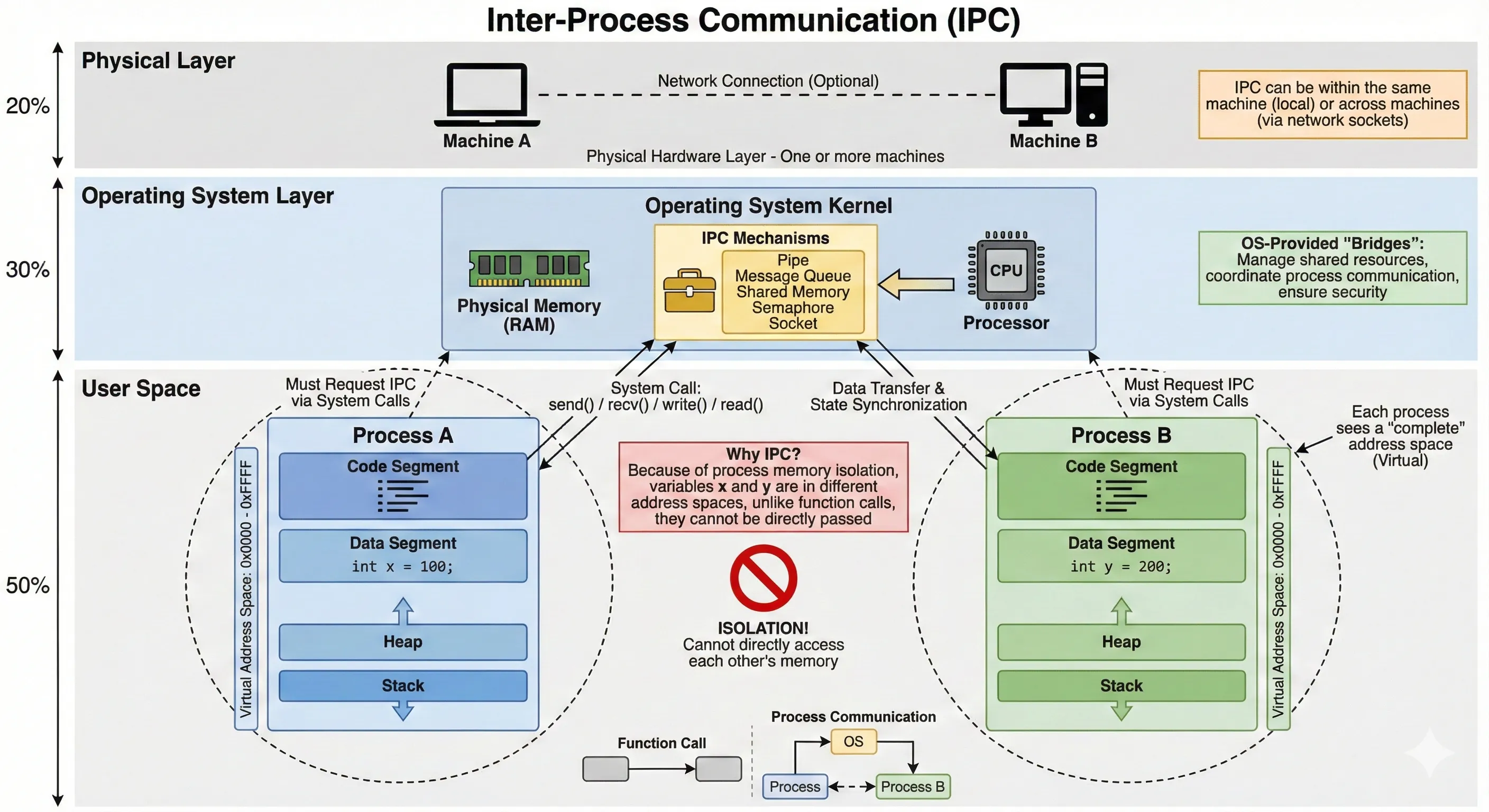
图解:IPC 概念架构
这张架构图从物理层到用户空间,展示了 IPC 如何作为桥梁解决隔离问题:
- 用户空间 (User Space):底部是两个相互隔离的 进程A 和 进程B。它们拥有独立的虚拟地址空间(0x0000 - 0xFFFF),中间的 “禁止符号” 代表无法直接访问对方内存(例如无法直接读取对方的
int y = 200)。- 操作系统层 (OS Layer):中间是操作系统内核,它维护着 IPC 工具箱(管道、消息队列、共享内存等)。
- 交互流程:
- 进程必须通过 系统调用 (Arrow UP:
send()/write()) 请求内核。- 内核利用 IPC 机制进行 数据传递与状态同步 (Arrow DOWN)。
- 物理层 (Physical Layer):顶层支持单机(Machine A)或跨网络(Machine A ⇄ Machine B)的通信基础。
一句话总结:因为内存隔离(Why),所以需要 OS 提供桥梁(How),既可是本地也可是远程(Where)。
不管是哪种方式,本质上都是在解决三类问题:
-
数据在不同地址空间之间怎么走?
- 拷贝(copy):管道、消息队列、socket 通常是“用户态 ⇄ 内核态 ⇄ 用户态两次拷贝”:
- 用户态缓冲区 → 内核缓冲区;
- 再从内核缓冲区 → 另一个进程的用户态缓冲区。
- 共享(share):共享内存是通过映射同一块物理页,不拷贝。
- 拷贝(copy):管道、消息队列、socket 通常是“用户态 ⇄ 内核态 ⇄ 用户态两次拷贝”:
-
如何保证同步和一致性?
- 阻塞 / 非阻塞 IO;
- 锁、信号量、自旋锁等原语;
- 自定义协议(版本号、序列号、心跳、重试)等逻辑保证。
-
如何标识对方并路由消息?
- 文件描述符(FD):管道、Unix Socket 等都依赖 FD;
- key / id:System V 消息队列 / 共享内存用 key;
- 网络地址:IP + 端口,外加一些 RPC 框架里的 service name。
换个角度看:所有 IPC 方案只是在这些维度上做不同权衡。
四、IPC 与“其他通信方式”的区别#
1. IPC vs 进程内通信(函数调用 / 线程共享内存)#
进程内(in-process)通信:
- 所有线程共享同一地址空间;
- 调用成本基本就是函数调用 + 内存访问;
- 只需要考虑锁、条件变量等同步手段。
IPC:
- 至少要跨一次内核(系统调用);
- 通常还要做序列化 / 拷贝;
- 但换来的是崩溃隔离、权限隔离、安全隔离。
一句话总结:
- 性能优先:进程内 > IPC;
- 隔离性和稳定性优先:IPC > 进程内。
很多大型系统都是两者混用:
- 同一个服务内部,用线程/协程共享内存;
- 服务与服务之间,用 IPC / 网络通信解耦。
2. IPC vs 网络通信(跨机器)#
从接口看,Unix Socket 和 TCP 很像;差别主要在 距离:
-
本地 IPC:
- 通常只跑在本机内核里,不出机器;
- 延迟低、带宽高;
- 配置简单(不需要 IP / 端口 / DNS 等)。
-
网络通信:
- 可以跨机器、跨机房;
- 多了路由、重传、拥塞控制、防火墙等复杂度;
- 更适合分布式 / 微服务。
很多系统会采取这样的策略:
- 单机内:组件之间用 Unix Socket 或共享内存;
- 跨机:再暴露一层 HTTP/gRPC API。
真实案例:Redis 的本地 vs 远程通信
import redis
# 方式 1:本地 Unix Socket(同一台机器,更快)
local_client = redis.Redis(unix_socket_path='/var/run/redis/redis.sock')
local_client.set('key', 'value') # 通过 Unix Socket
# 方式 2:TCP 连接(可跨机器)
remote_client = redis.Redis(host='redis.example.com', port=6379)
remote_client.set('key', 'value') # 通过 TCP/IP
# 同样的 API,底层 IPC 方式不同
# 性能差异:Unix Socket 延迟约 0.05ms,TCP loopback 约 0.1msDocker 的 Socket 通信模式
# Docker CLI 默认通过 Unix Socket 和 dockerd 通信
$ ls -la /var/run/docker.sock
srw-rw---- 1 root docker 0 Dec 9 10:00 /var/run/docker.sock
# docker 命令实际是 HTTP over Unix Socket
$ curl --unix-socket /var/run/docker.sock http://localhost/containers/json
[{"Id":"abc123...","Names":["/my-container"],...}]
# 远程访问时切换为 TCP
$ docker -H tcp://remote-host:2375 ps设计模式:很多系统(Docker、MySQL、PostgreSQL、Redis)都支持 Unix Socket 和 TCP 两种模式,让用户根据部署场景选择。
3. 各种 IPC 方式之间的对比(速查表)#
| 方式 | 特点 | 适用场景 |
|---|---|---|
| 管道 | 简单、流式、小数据、父子进程 | 简单的“流水线”式生产者-消费者 |
| 消息队列 | 有消息边界、多生产者/消费者、适合解耦 | 多生产者-多消费者、逻辑清晰 |
| 共享内存 | 最高性能,大块数据;但同步复杂 | 数据量很大、频繁读写、性能敏感 |
| 信号量/锁 | 不传数据,负责“协调访问” | 配合共享内存,做同步保护 |
| 信号 | 异步通知,用来“拍一下”对方 | 通知进程“发生了一件事” |
| Unix Socket | 通用且灵活、本地和网络可统一代码 | 想要 Socket 接口体验,或者为了未来扩展 |
| RPC / D-Bus | 高级封装,接口像“调用函数” | 复杂系统集成,需要服务发现和类型安全 |
五、怎么选用 IPC 方式?#
按场景分类:
-
大数据、高频率、本机共享
➜ 共享内存 + 锁 / 信号量
例:多进程共享一块缓存,读多写少。 -
简单父子进程通信 / 日志 / 命令输出
➜ 匿名管道(pipe)即可
例:一个主进程 fork 出 worker,worker 把结果写回主进程。 -
多个生产者/消费者、逻辑层次清晰
➜ 消息队列(内核队列或者中间件 MQ)
例:日志采集、多模块异步事件。 -
服务化通信,未来可能要跨机器
➜ 本机用 Unix Socket,远程用 TCP/HTTP + RPC 框架
例:数据库前端进程和存储进程、Nginx worker 和 master。 -
只需要“拍一下对方”,不需要带数据
➜ 信号 / 简单事件机制
例:给服务发 SIGTERM 告诉它优雅退出;让守护进程知道子进程挂了。
六、一句话记 IPC#
简化版“速记卡”:
IPC = 地址空间隔离下的“说话方式”。
进程看不到彼此内存,只能通过内核提供的管道、消息队列、共享内存、socket 等桥梁交换数据。
选型时,在“性能 / 简单 / 隔离 / 跨机器”之间做权衡就好。
延伸阅读:Claude Agent SDK 的 IPC 实战解析#
如果你对「IPC 在真实框架里怎么用」感兴趣,可以结合我之前写的 Claude SDK 源码分析一起看:
架构总览#
Claude Agent SDK 的核心设计:Python SDK 不直接调用 HTTP API,而是:
┌─────────────────────┐ stdin (JSON Lines) ┌──────────────────────┐ HTTPS
│ 你的 Python 应用 │ ─────────────────────────► │ claude CLI 子进程 │ ────────────► Anthropic API
│ (SDK 用户代码) │ ◄───────────────────────── │ (Node.js 二进制) │ ◄────────────
└─────────────────────┘ stdout (JSON Lines) └──────────────────────┘
│ │
└───── 匿名管道 (Anonymous Pipe) ────────────────────┘从 IPC 角度看,这是一个典型的 管道 + 文本协议 方案:
- 传输层:匿名管道(stdin/stdout)
- 协议层:JSON Lines(一行一条消息)
- 语义层:定义了
tool_use、tool_result、control_request等消息类型
1. 数据传输:子进程启动与管道建立#
核心问题:数据怎么从 Python 进程跑到 CLI 进程?
SDK 使用 anyio.open_process 启动子进程,并通过 stdin/stdout 参数设置管道:
源码:subprocess_cli.py - SubprocessCLITransport 类
class SubprocessCLITransport(Transport):
"""
基于子进程的传输层实现。
核心思路:启动 claude CLI 作为子进程,通过 stdin/stdout 管道通信。
"""
async def connect(self) -> None:
"""建立与 CLI 子进程的连接"""
# 1. 构建完整的命令行参数
cmd = self._build_command()
# 2. 准备进程环境变量(继承当前环境 + SDK 特定变量)
process_env = {**os.environ}
if self._options.api_key:
process_env["ANTHROPIC_API_KEY"] = self._options.api_key
# 3. 启动子进程,关键在于 stdin=PIPE, stdout=PIPE
# 这会让内核创建两个匿名管道:
# - 一个用于父进程写 → 子进程读(stdin)
# - 一个用于子进程写 → 父进程读(stdout)
self._process = await anyio.open_process(
cmd,
stdin=PIPE, # ← 创建 stdin 管道
stdout=PIPE, # ← 创建 stdout 管道
stderr=stderr_dest,
cwd=self._cwd,
env=process_env,
user=self._options.user,
)
# 4. 包装管道为异步文本流
# TextReceiveStream / TextSendStream 处理字节到文本的转换
if self._process.stdout:
self._stdout_stream = TextReceiveStream(self._process.stdout)
if self._is_streaming and self._process.stdin:
self._stdin_stream = TextSendStream(self._process.stdin)
self._ready = TrueIPC 知识点:
anyio.open_process底层调用os.pipe()创建管道,然后fork()+exec()启动子进程。管道的文件描述符会被重定向到子进程的 stdin/stdout。
2. 消息写入:序列化与发送#
核心问题:如何把 Python 对象发送给 CLI?
SDK 将消息序列化为 JSON,通过管道写入:
源码:写入逻辑
async def write(self, data: str) -> None:
"""
向 CLI 子进程发送一条消息。
Args:
data: 已序列化的 JSON 字符串(不含换行符)
注意事项:
- 使用锁保证多个协程不会同时写入(避免消息交错)
- JSON Lines 格式:每条消息占一行,以 \n 结尾
"""
async with self._write_lock: # ← 互斥锁,防止并发写入导致消息混乱
if not self._ready or not self._stdin_stream:
raise CLIConnectionError("ProcessTransport is not ready for writing")
# 发送消息,TextSendStream 会自动添加换行符
await self._stdin_stream.send(data)
# 调用示例:发送工具调用结果
async def send_tool_result(self, tool_call_id: str, result: dict) -> None:
"""发送工具执行结果给 CLI"""
message = {
"type": "tool_result",
"tool_call_id": tool_call_id,
"content": result,
"timestamp": time.time(),
}
await self.write(json.dumps(message)) # ← 序列化为 JSON 字符串为什么用 JSON Lines 而不是 Protocol Buffer?
- 文本可读、易调试(直接
cat管道内容就能看)- 无需预编译 schema
- 对于控制类消息,性能足够
3. 消息读取:流式解析与事件分发#
核心问题:如何从管道读取并解析消息流?
这是最复杂的部分,需要处理:
- 流式读取(消息可能跨多次 read 调用)
- JSON 边界检测(一行一条消息)
- 缓冲区溢出保护
源码:读取逻辑
async def read_messages(self) -> AsyncGenerator[dict, None]:
"""
从 CLI 子进程读取消息流。
Yields:
解析后的消息字典
实现细节:
- 按行读取(JSON Lines 格式)
- 累积不完整的 JSON 直到可以解析
- 防止恶意/错误输出撑爆内存
"""
json_buffer = "" # 累积缓冲区,处理跨行的 JSON
async for line in self._stdout_stream:
line_str = line.strip()
if not line_str:
continue # 跳过空行
# 一行可能包含多条 JSON(虽然不常见)
for json_line in line_str.split("\n"):
json_buffer += json_line.strip()
# 安全检查:防止缓冲区无限增长
if len(json_buffer) > self._max_buffer_size:
raise SDKJSONDecodeError(
f"JSON message exceeded maximum buffer size of {self._max_buffer_size} bytes",
ValueError(f"Buffer size {len(json_buffer)} exceeds limit"),
)
# 尝试解析 JSON
try:
data = json.loads(json_buffer)
json_buffer = "" # 成功解析,清空缓冲区
yield data # 返回解析后的消息
except json.JSONDecodeError:
# 不完整的 JSON,继续累积
continueIPC 知识点:管道是字节流,没有消息边界。JSON Lines 协议通过换行符
\n来标记消息边界,但一次read()可能返回多条消息或者半条消息,所以需要缓冲区处理。
4. 消息路由:请求-响应匹配#
核心问题:如何把响应路由到正确的请求?
SDK 使用 request_id 机制实现请求-响应匹配:
源码:query.py - 消息分发逻辑
class QuerySession:
"""管理一次完整的对话会话"""
def __init__(self):
# 待处理的控制请求:request_id -> Event
self.pending_control_responses: dict[str, anyio.Event] = {}
# 控制请求的结果:request_id -> response
self.pending_control_results: dict[str, Any] = {}
async def process_messages(self) -> None:
"""
消息处理主循环。
消息类型:
- control_response: SDK 发出的控制请求的响应(如权限请求)
- tool_use: CLI 请求调用某个工具
- assistant_message: 模型生成的文本
- error: 错误消息
"""
async for message in self.transport.read_messages():
msg_type = message.get("type")
# 1. 控制响应:匹配到等待中的请求
if msg_type == "control_response":
response = message.get("response", {})
request_id = response.get("request_id")
if request_id in self.pending_control_responses:
# 找到对应的等待事件
event = self.pending_control_responses[request_id]
# 存储结果(可能是成功或错误)
if response.get("subtype") == "error":
self.pending_control_results[request_id] = Exception(
response.get("error", "Unknown error")
)
else:
self.pending_control_results[request_id] = response
event.set() # ← 唤醒等待的协程
continue
# 2. 工具调用请求
if msg_type == "tool_use":
tool_call_id = message.get("id")
tool_name = message.get("name")
tool_input = message.get("input", {})
# 执行工具并发送结果
result = await self._execute_tool(tool_name, tool_input)
await self.transport.send_tool_result(tool_call_id, result)
continue
# 3. 其他消息:发送到消息通道供上层消费
await self._message_send.send(message)
async def send_control_request(self, request: dict) -> dict:
"""
发送控制请求并等待响应(同步语义)。
实现:
1. 生成唯一 request_id
2. 注册等待事件
3. 发送请求
4. 等待响应
"""
request_id = str(uuid.uuid4())
request["request_id"] = request_id
# 创建等待事件
event = anyio.Event()
self.pending_control_responses[request_id] = event
# 发送请求
await self.transport.write(json.dumps(request))
# 等待响应(带超时)
with anyio.fail_after(self._timeout):
await event.wait()
# 获取结果
result = self.pending_control_results.pop(request_id)
del self.pending_control_responses[request_id]
if isinstance(result, Exception):
raise result
return result设计模式:这是典型的 异步请求-响应匹配 模式,常见于 RPC 框架。通过
request_id将请求和响应关联起来,允许多个请求并发进行。
5. 完整消息流示例#
下面是一次工具调用的完整消息流:
Python SDK CLI 子进程 Anthropic API
│ │ │
│──── stdin ────────────────────────│ │
│ {"type": "user_message", │ │
│ "content": "查看当前目录"} │ │
│ │──── HTTPS ────────────────────────│
│ │ POST /v1/messages │
│ │ {...} │
│ │ │
│ │◄─── HTTPS ────────────────────────│
│ │ {"type": "tool_use", │
│ │ "name": "bash", ...} │
│◄─── stdout ───────────────────────│ │
│ {"type": "tool_use", │ │
│ "id": "call_123", │ │
│ "name": "bash", │ │
│ "input": {"command": "ls"}} │ │
│ │ │
│ [SDK 执行 bash 命令] │ │
│ │ │
│──── stdin ────────────────────────│ │
│ {"type": "tool_result", │ │
│ "tool_call_id": "call_123", │──── HTTPS ────────────────────────│
│ "content": "file1.txt\n..."} │ POST /v1/messages (继续) │
│ │ │SDK 架构小结#
从 IPC 视角看,Claude Agent SDK 是一个教科书级的 管道 + 文本协议 实现:
| IPC 三大问题 | Claude SDK 的解法 |
|---|---|
| 数据怎么传? | 匿名管道(stdin/stdout),JSON Lines 格式 |
| 如何同步? | 写锁 + 请求-响应匹配(request_id) |
| 如何路由? | 消息类型(type) + 调用 ID(tool_call_id) |
这种设计的优势:
- 进程隔离:CLI 崩溃不会拖垮 Python 进程
- 能力复用:CLI 已有完整的权限管理、MCP 支持、工具系统
- 版本独立:升级 CLI 不需要更新 SDK
代价:
- 依赖 CLI:必须安装
@anthropic-ai/claude-code - 调试复杂:问题可能在 SDK、CLI 或 API 任何一层