形式化建模:SFT 是外部数据分布上的前向 KL 投影#
1. 阅读指南#
1.1 本节具体性质#
为了避免后文定理读起来像“只是在换符号”,先把本文想强调的四个性质直接写出来:
- 可识别性性质:任何后训练目标都只能识别其加权到的 states;未被状态权重测度看到的 states,不可能由该目标单独约束。
- 三元组决定性:一旦某方法能写成“状态分布 ν + 目标分布 ξs + 散度 D”,那么它在 supp(ν) 上的理想最优行为就由这三个对象完全决定,算法名字只影响数值求解路径。
- 遗忘的必要条件:若旧能力主要依赖于 supp(ν) 之外的状态,那么任何只在 ν 上训练的方法,都无法从目标函数本身推出 retention 保证。
- 泛化的必要条件:要把训练误差转成部署误差,必须额外比较训练状态分布与部署状态分布;只看 token loss、reward 大小或“是否有 teacher”本身都不够。
这四条并不是新的定理,而是全文后续结果的阅读指南:后面的所有证明,本质上都在把这四句从直觉改写成精确公式。
2. 形式化建模#
2.1 把自回归语言模型写成有限时域决策过程#
定义 2.1(提示、动作、状态). 设 X 为 prompt 集合,A 为 token 动作集合,包含特殊终止符 EOS。设最大生成步数为 H∈N。
在第 t 步,状态记为
st=(x,a<t)=(x,a1,…,at−1),
其中 x∈X,ai∈A。因此状态就是“prompt + 当前前缀”。
注记 2.2. 为了避免可变长序列引入不必要的技术细节,本文采用“最大长度 H,遇到 EOS 后进入吸收终止态”的标准处理。这样可以把每条轨迹都看成长度恰为 H 的序列,而不影响终止前的自回归部分。
定义 2.3(策略). 一个语言模型策略 π 是从状态到动作分布的映射:
π(⋅∣s)∈Δ(A),s∈S.
其中 Δ(A) 表示动作单纯形。若用 logits zπ(s,a) 参数化,则
π(a∣s)=∑b∈Aexp(zπ(s,b))exp(zπ(s,a)).
定义 2.4(轨迹分布). 设 prompt 分布为 ρ(x)。给定策略 π,一条轨迹记为
τ=(x,a1,…,aH).
其条件概率为
Pπ(τ)=ρ(x)t=1∏Hπ(at∣st),st=(x,a<t).
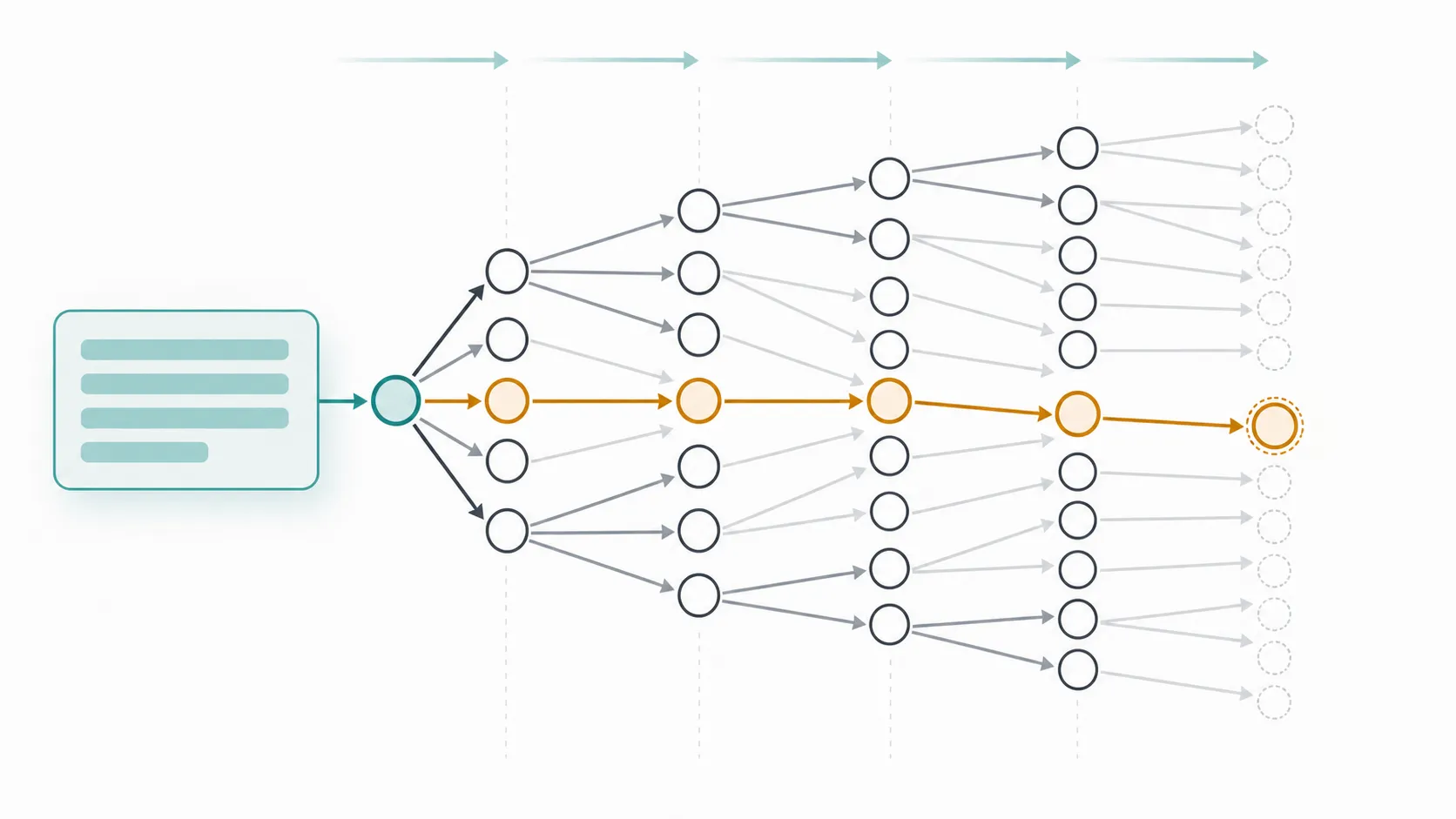
图 1:有限时域决策过程的直观图。左侧是 prompt,右侧是由 token 动作展开的前缀树;橙色路径表示一条具体轨迹,灰色分支表示同一状态下其他可能动作。
定义 2.5(状态-动作边缘、占用测度). 定义策略 π 的状态-动作边缘为
qπ(s,a):=τ∑Pπ(τ)t=1∑H1{st=s, at=a}.
定义对应的状态占用测度
dπ(s):=a∈A∑qπ(s,a)=τ∑Pπ(τ)t=1∑H1{st=s}.
定义归一化占用分布
dˉπ(s):=H1dπ(s)=H1t=1∑HπPr(st=s).
注记 2.6. dπ 不是概率分布,它的总质量是 H;dˉπ 才是概率分布。本文凡是讨论总变差(TV)或分布失配时,都优先使用 dˉπ。
引理 2.7(对轨迹求和与对占用测度求和是等价的). 对任意函数 f:S×A→R,
Eτ∼Pπ[t=1∑Hf(st,at)]=s∈S∑a∈A∑qπ(s,a)f(s,a).
若 g:S→R 只依赖状态,则
Eτ∼Pπ[t=1∑Hg(st)]=s∈S∑dπ(s)g(s).
证明. 直接展开:
Eτ∼Pπ[t=1∑Hf(st,at)]=τ∑Pπ(τ)t=1∑Hf(st,at)=τ∑Pπ(τ)t=1∑Hs,a∑1{st=s, at=a}f(s,a)=s,a∑(τ∑Pπ(τ)t=1∑H1{st=s, at=a})f(s,a)=s,a∑qπ(s,a)f(s,a).
第二式令 f(s,a)=g(s) 即得。
2.2 外部数据分布与经验数据策略#
定义 2.8(数据轨迹分布). 设 Q 是一个外部数据分布,例如人工标注答案、teacher 生成答案、混合示范集等。它给出轨迹 τ=(x,a1,…,aH) 的概率 Q(τ)。
与策略分布完全同理,定义数据的状态-动作边缘
qQ(s,a):=τ∑Q(τ)t=1∑H1{st=s, at=a},dQ(s):=a∑qQ(s,a),
dˉQ(s):=H1dQ(s).
定义 2.9(经验数据策略). 对所有满足 dQ(s)>0 的状态,定义经验数据策略
μQ(a∣s):=dQ(s)qQ(s,a).
若 dQ(s)=0,则 μQ(⋅∣s) 可任意指定,因为该状态在所有相关目标中权重为 0。
注记 2.10. 当每个 (s) 只出现一个标注 token 时,μQ(⋅∣s) 就是 one-hot 分布;当有多参考答案、软标签、或 teacher logits 时,μQ(⋅∣s) 就是一般分布。因此“硬标签 SFT”和“软标签蒸馏”在数学上只差一个 target 分布是否为 one-hot。
2.3 本文用到的散度与算子#
定义 2.11(交叉熵、前向 KL、反向 KL、总变差). 对定义在 A 上的两个分布 p,q:
交叉熵定义为
H(p,q):=−a∈A∑p(a)logq(a).
前向 KL 定义为
DKL(p∥q):=a∈A∑p(a)logq(a)p(a).
反向 KL 在符号上就是交换顺序:
DKL(q∥p):=a∈A∑q(a)logp(a)q(a).
总变差定义为
TV(p,q):=21a∈A∑∣p(a)−q(a)∣.
注记 2.12. 注意:工程里常说“forward KL / reverse KL”,本质上只是两个参数顺序不同;本文会明确写成 DKL(p∥q) 或 DKL(q∥p),避免口头混淆。
2.4 本节具体性质#
命题 2.13(占用测度的归一化与因子分解). 对任意策略 π,
s∈S∑dπ(s)=H,s∈S∑a∈A∑qπ(s,a)=H,qπ(s,a)=dπ(s)π(a∣s).
同理,对任意外部数据分布 Q,
s∑dQ(s)=H,s,a∑qQ(s,a)=H,qQ(s,a)=dQ(s)μQ(a∣s).
因此 dˉπ 与 dˉQ 都是概率分布:
s∑dˉπ(s)=1,s∑dˉQ(s)=1.
证明. 先证策略情形。由定义
dπ(s)=τ∑Pπ(τ)t=1∑H1{st=s}.
对 s 求和:
s∑dπ(s)=s∑τ∑Pπ(τ)t=1∑H1{st=s}=τ∑Pπ(τ)t=1∑Hs∑1{st=s}=τ∑Pπ(τ)t=1∑H1=Hτ∑Pπ(τ)=H.
同理,
s,a∑qπ(s,a)=τ∑Pπ(τ)t=1∑Hs,a∑1{st=s, at=a}=H.
再证因子分解。因为在给定状态 st=s 时,下一动作由 π(⋅∣s) 采样,
πPr(st=s, at=a)=πPr(st=s)π(a∣s).
对所有可能的时间步求和即可得
qπ(s,a)=dπ(s)π(a∣s).
数据分布 Q 的情形完全同理;只是把 π(a∣s) 替换成经验条件分布 μQ(a∣s)。
命题 2.14(前缀概率的显式形式与支持传播). 设某个状态写成
s=(x,a<t)=(x,a1,…,at−1).
则该状态在第 t 步被访问到的概率满足
πPr(st=s)=ρ(x)i=1∏t−1π(ai∣x,a<i).
因此,若 Prπ(st=s)>0 且 π(at∣s)>0,则后继状态
s′=(x,a≤t)=(x,a1,…,at)
也满足
πPr(st+1=s′)>0.
证明. 按轨迹分布的定义,状态 st=(x,a<t) 在第 t 步出现,当且仅当 prompt 等于 x 且前 t−1 个 token 恰为 a1,…,at−1。于是
πPr(st=s)=ρ(x)i=1∏t−1π(ai∣x,a<i).
进一步,
πPr(st+1=s′)=ρ(x)i=1∏tπ(ai∣x,a<i)=πPr(st=s)π(at∣s).
若右侧两因子都为正,则结论成立。
注记 2.15. 命题 2.13 与命题 2.14 给出了两个以后会反复用到的“基础性质”:一是所有目标都可以写成对占用测度的加权和;二是状态支持集会沿着正概率前缀向后传播。
3. SFT:外部数据分布上的前向 KL 投影#
3.1 目标函数展开#
定义 3.1(SFT 目标). 给定外部数据分布 Q,SFT 目标写成
LSFT(π):=Eτ∼Q[−t=1∑Hlogπ(at∣st)].
定理 3.2(SFT 的精确分解). SFT 目标可以精确写成
LSFT(π)=s∈S∑dQ(s)H(μQ(⋅∣s),π(⋅∣s)),
以及
LSFT(π)=CQ+s∈S∑dQ(s)DKL(μQ(⋅∣s)∥π(⋅∣s)),
其中常数项
CQ:=s∈S∑dQ(s)H(μQ(⋅∣s))
与 π 无关。
证明. 逐步展开:
LSFT(π)=Eτ∼Q[−t=1∑Hlogπ(at∣st)]=−τ∑Q(τ)t=1∑Hlogπ(at∣st)=−τ∑Q(τ)t=1∑Hs,a∑1{st=s, at=a}logπ(a∣s)=−s,a∑(τ∑Q(τ)t=1∑H1{st=s, at=a})logπ(a∣s)=−s,a∑qQ(s,a)logπ(a∣s).
利用 qQ(s,a)=dQ(s)μQ(a∣s),
LSFT(π)=−s∑dQ(s)a∑μQ(a∣s)logπ(a∣s)=s∑dQ(s)H(μQ,π).
再利用恒等式
H(μQ,π)=H(μQ)+DKL(μQ∥π),
得到
LSFT(π)=s∑dQ(s)H(μQ(⋅∣s))+s∑dQ(s)DKL(μQ(⋅∣s)∥π(⋅∣s)).
第一项与 π 无关,即为常数 CQ。
推论 3.3(SFT 是对经验数据策略的 off-policy distillation). 若把 μQ(⋅∣s) 看成“经验 teacher”,则 SFT 正是在外部状态分布 dQ 上,对 teacher 条件分布做前向 KL 投影。
证明. 由定理 3.2,优化 LSFT 等价于最小化
s∑dQ(s)DKL(μQ(⋅∣s)∥π(⋅∣s)).
这正是前向 KL distillation,只不过 teacher 不是一个显式模型,而是数据经验分布 μQ。
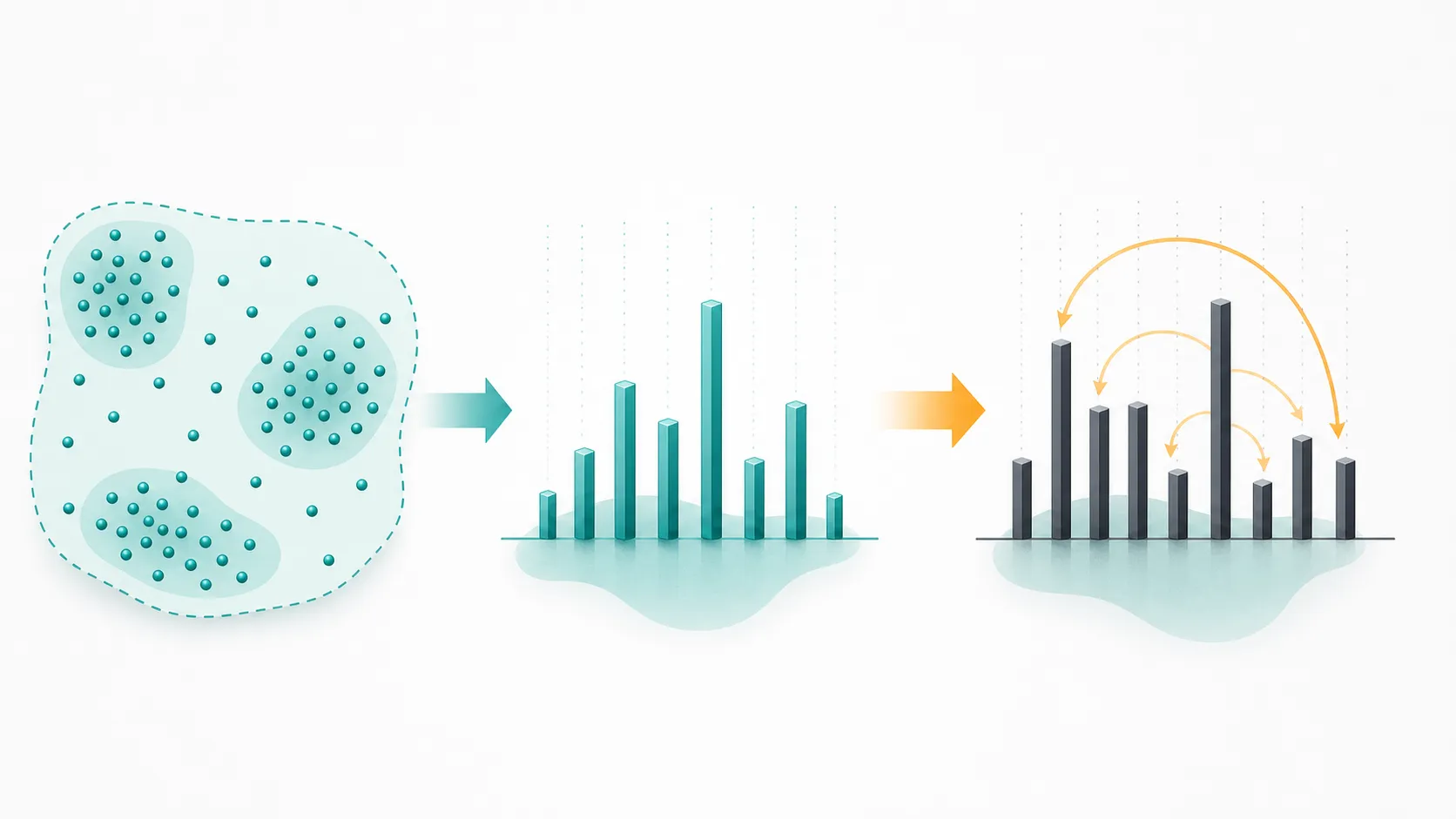
图 2:SFT 的 off-policy distillation 视角。左侧是外部数据覆盖到的状态支持,中间是经验 target 分布 μQ(⋅∣s),右侧是被前向 KL 拉向 target 的模型分布 π(⋅∣s)。
3.2 SFT 最优解与其“只约束数据支持集”的性质#
定理 3.4(SFT 的非参数最优解). 若把优化域看成所有随机策略的集合,则
argπminLSFT(π)={π:π(⋅∣s)=μQ(⋅∣s)∀s with dQ(s)>0}.
在所有 dQ(s)=0 的状态上,SFT 目标没有任何约束。
证明. 由定理 3.2,
LSFT(π)=CQ+s∑dQ(s)DKL(μQ∥π).
每一项 KL 非负,且当且仅当 π(⋅∣s)=μQ(⋅∣s) 时取 0。对 dQ(s)=0 的状态,对应项恒为 0,所以不约束这些状态。
命题 3.5(SFT 在数据支持集外完全不敏感). 若两个策略 π,π~ 满足
π(⋅∣s)=π~(⋅∣s)∀s∈supp(dQ),
则
LSFT(π)=LSFT(π~).
证明. 由定理 3.2,SFT 目标只对所有满足 dQ(s)>0 的状态求和;在其余状态上的策略如何变化都不会进入目标函数。
注记 3.6. 这条命题几乎就是“灾难性遗忘为何可能发生”的最直接数学表述:如果旧能力对应的 states 不在当前 SFT 数据支持集里,SFT 目标对这些旧 states 没有任何显式约束。
3.3 SFT 梯度的完整展开#
固定某个状态 s,记
pi:=π(ai∣s),qi:=μQ(ai∣s),pi=∑jezjezi.
对应的局部 SFT 损失为
ℓSFT(s)=−i∑qilogpi.
引理 3.7(softmax 雅可比). 对 softmax 输出 pi=∑jezjezi,有
∂zk∂pi=pi(δik−pk),
其中 δik 是 Kronecker delta。
证明. 记 Z=∑jezj,则 pi=ezi/Z。对 zk 求导:
∂zk∂pi=Z2δikeziZ−eziezk=Zezi(δik−Zezk)=pi(δik−pk).
定理 3.8(SFT 对 logits 的梯度). 对固定状态 s,局部损失 ℓSFT(s) 关于 logit zk 的梯度为
∂zk∂ℓSFT(s)=pk−qk.
因此全局损失满足
∂z(s,ak)∂LSFT=dQ(s)(π(ak∣s)−μQ(ak∣s)).
证明. 直接对
ℓSFT(s)=−i∑qilogpi
求导:
∂zk∂ℓSFT(s)=−i∑qipi1∂zk∂pi=−i∑qipi1pi(δik−pk)=−i∑qiδik+i∑qipk=−qk+pki∑qi=pk−qk,
因为 ∑iqi=1。再乘上全局权重 dQ(s) 即得。
注记 3.9. 这条公式说明 SFT 的更新方向完全由数据状态权重 dQ(s) 决定。出现次数高的状态梯度大,没出现的状态梯度严格为零。
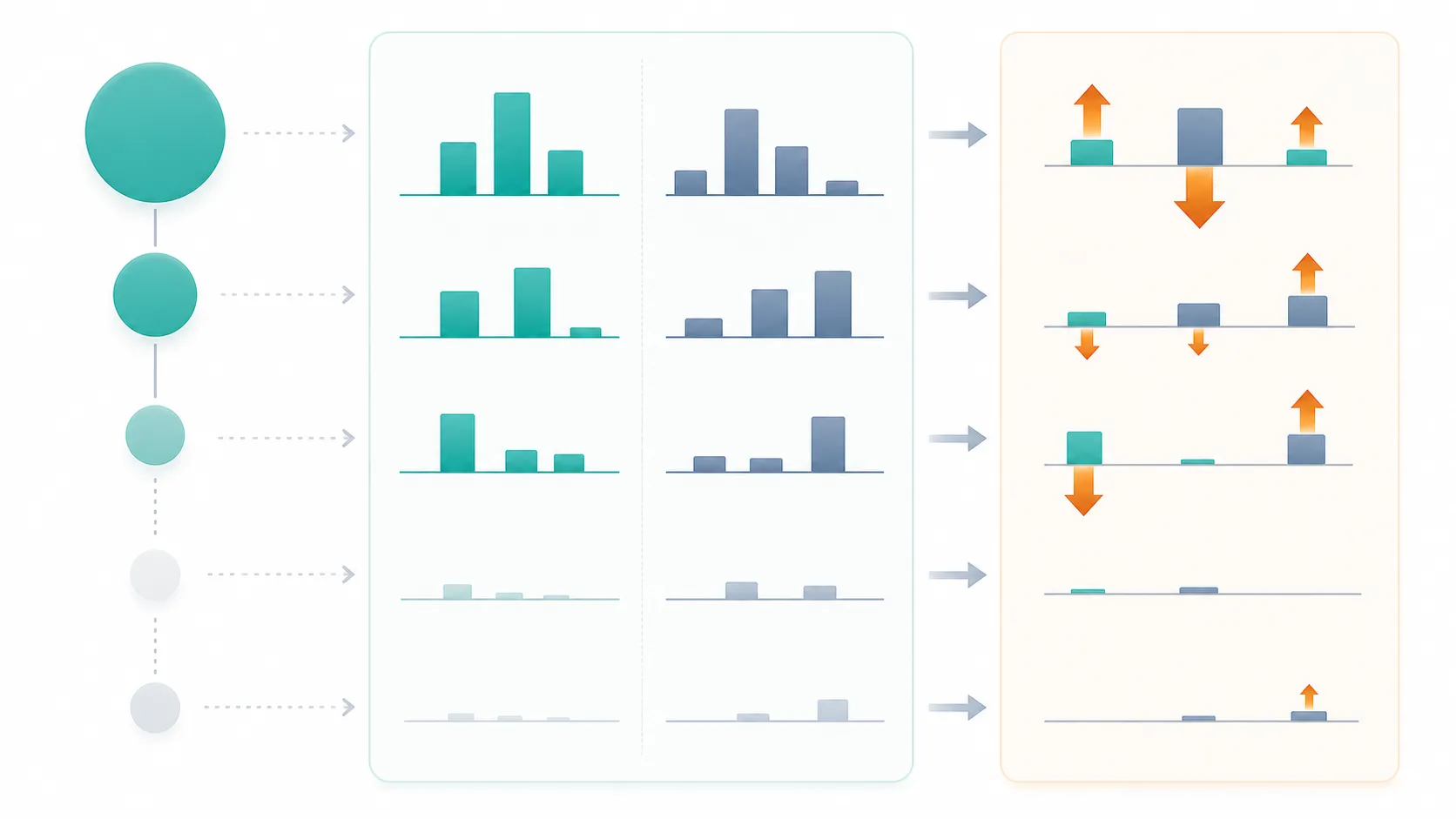
图 3:SFT logits 梯度的直观图。每个状态内部比较 π(⋅∣s) 与 μQ(⋅∣s);差值决定 token 概率往上还是往下调,而左侧状态圆点大小表示 dQ(s) 对梯度强度的加权。
3.4 本节具体性质#
性质 3.A(one-hot 标签是 SFT 的特例). 若某个数据状态 s 上只有一个标注 token a⋆,即
μQ(a⋆∣s)=1,μQ(a∣s)=0(a=a⋆),
则局部交叉熵退化为普通 hard-label 负对数似然:
H(μQ,π)=−logπ(a⋆∣s).
对应的 logit 梯度为
∂z(s,a)∂ℓSFT(s)=π(a∣s)−1{a=a⋆}.
因此 hard-label SFT 不是另一个目标,而是 μQ 为 one-hot 时的特例。
性质 3.B(前向 KL 对数据动作的零概率敏感). 对任意满足 dQ(s)>0 的状态,如果存在动作 a 使得
μQ(a∣s)>0,π(a∣s)=0,
则
DKL(μQ(⋅∣s)∥π(⋅∣s))=+∞.
这说明前向 KL 会强烈惩罚“数据里出现过的动作被模型分配零概率”。在有限 logits 的 softmax 参数化下,π(a∣s) 不会真的等于 0,但当它趋近于 0 时,该项会迅速变大。
性质 3.C(SFT 不直接约束 rollout 状态分布失配). 设 h:S→R 是任意有界状态函数,且 ∣h(s)∣≤M。则
s∑dˉπ(s)h(s)−s∑dˉQ(s)h(s)≤2MTV(dˉπ,dˉQ).
SFT 目标直接优化的是外部状态权重 dQ(s) 下的条件分布匹配,而不是 dˉπ 与 dˉQ 的接近程度。因此,当训练数据状态分布和模型 rollout 状态分布相差很大时,即使数据支持集上的 token loss 很低,模型在自己生成出来的新前缀上仍然可能缺少约束。
证明. 由总变差定义,
s∑(dˉπ(s)−dˉQ(s))h(s)≤s∑∣dˉπ(s)−dˉQ(s)∣∣h(s)∣≤Ms∑∣dˉπ(s)−dˉQ(s)∣=2MTV(dˉπ,dˉQ).
性质 3.D(logits 梯度在每个状态内质量守恒). 对固定状态 s,局部梯度满足
k∑∂zk∂ℓSFT(s)=0.
证明. 由定理 3.8,
k∑(pk−qk)=k∑pk−k∑qk=1−1=0.
这也对应 softmax 的平移不变性:给同一个状态下所有 logits 同时加上常数,不会改变策略分布。
性质 3.E(数据频次只改变梯度权重,不改变局部方向). 若两个状态 s1,s2 的局部分布差相同,即
π(⋅∣s1)−μQ(⋅∣s1)=π(⋅∣s2)−μQ(⋅∣s2),
则它们在全局 SFT 梯度中的比例只由 dQ 决定:
∂LSFT/∂z(s2,a)∂LSFT/∂z(s1,a)=dQ(s2)dQ(s1)
在分母非零时成立。因此,SFT 的“更重视哪些状态”完全来自数据占用频次或采样权重。
命题 3.10(SFT 的局部 Hessian 是 Fisher 矩阵). 对固定状态 s,局部 SFT 损失
ℓSFT(s)=−i∑qilogpi
关于 logits z=(zi)i 的 Hessian 为
∂zk∂zℓ∂2ℓSFT(s)=pk(δkℓ−pℓ).
矩阵形式写成
∇z2ℓSFT(s)=Diag(p)−pp⊤⪰0.
其零空间正是常数平移方向 span{1}。
证明. 由定理 3.8,
∂zk∂ℓSFT(s)=pk−qk.
再对 zℓ 求导即可:
∂zk∂zℓ∂2ℓSFT(s)=∂zℓ∂pk=pk(δkℓ−pℓ),
其中最后一步用了引理 3.7。把所有分量拼成矩阵就是
Diag(p)−pp⊤.
对任意向量 v,
v⊤(Diag(p)−pp⊤)v=i∑pivi2−(i∑pivi)2=Vara∼p[va]≥0,
故该矩阵半正定。等号成立当且仅当 va 在 p 的支持集上为常数;在有限 logits 的 softmax 参数化下,p 对所有动作都有正质量,因此零空间是常数平移方向。
推论 3.11(SFT 的局部凸性与概率空间唯一最优解). 固定一个状态 s。SFT 局部损失对 logits 是凸的;若改在概率单纯形上看,则其唯一最优解为
p⋆=q=μQ(⋅∣s).
证明. 凸性由命题 3.10 的 Hessian 半正定得到。又因为
ℓSFT(s)=H(q)+DKL(q∥p),
最小值在且仅在 DKL(q∥p)=0 时取得,即 p=q。
命题 3.12(软标签与标签平滑的线性性). 设两个目标分布为 q(1),q(2),以及混合目标
q(λ):=(1−λ)q(1)+λq(2),λ∈[0,1].
则对任意预测分布 p,
H(q(λ),p)=(1−λ)H(q(1),p)+λH(q(2),p).
因此,软标签蒸馏、多个参考答案平均、标签平滑等,都只是 forward-KL 目标在线性空间里的不同取值。
证明. 直接展开即可:
H(q(λ),p)=−a∑((1−λ)q(1)(a)+λq(2)(a))logp(a)=(1−λ)(−a∑q(1)(a)logp(a))+λ(−a∑q(2)(a)logp(a)).
注记 3.13. 本节最值得记住的三个具体性质是:SFT 对 logits 的二阶结构是 Fisher 矩阵;SFT 在概率空间上唯一追向数据分布本身;而只要目标分布做凸组合,SFT 损失就按同样系数线性组合。
附录 A:几个最小代码验证#
A.1 验证 SFT 分解与 logits 梯度#
下面这个 PyTorch 例子同时验证两件事:
- SFT soft-label 交叉熵等于常数熵项加前向 KL。
- logits 梯度等于 dQ(s)(π−μQ)。
import torch
torch.manual_seed(0)
num_states = 3
num_actions = 5
logits = torch.randn(num_states, num_actions, requires_grad=True)
mu_q = torch.softmax(torch.randn(num_states, num_actions), dim=-1)
d_q = torch.tensor([4.0, 2.0, 0.0])
pi = torch.softmax(logits, dim=-1)
cross_entropy = -(mu_q * torch.log(pi)).sum(dim=-1)
loss = (d_q * cross_entropy).sum()
entropy = -(mu_q * torch.log(mu_q)).sum(dim=-1)
forward_kl = (mu_q * (torch.log(mu_q) - torch.log(pi))).sum(dim=-1)
decomposed = (d_q * (entropy + forward_kl)).sum()
print(torch.allclose(loss, decomposed, atol=1e-6))
loss.backward()
expected_grad = d_q[:, None] * (pi.detach() - mu_q)
print(torch.allclose(logits.grad, expected_grad, atol=1e-6))
print(logits.grad)
python其中 d_q[2] = 0,所以第三个状态即使有 logits,也不会产生梯度。
A.2 hard-label SFT 是 one-hot soft-label 的特例#
import torch
import torch.nn.functional as F
torch.manual_seed(0)
batch = 4
vocab = 6
logits = torch.randn(batch, vocab)
targets = torch.tensor([2, 3, 3, 0])
hard_label_loss = F.cross_entropy(logits, targets, reduction="none")
one_hot_targets = F.one_hot(targets, num_classes=vocab).float()
soft_label_loss = -(one_hot_targets * F.log_softmax(logits, dim=-1)).sum(dim=-1)
print(hard_label_loss)
print(soft_label_loss)
print(torch.allclose(hard_label_loss, soft_label_loss, atol=1e-6))
python这段代码对应性质 3.A:普通 token-level cross entropy 只是 μQ 取 one-hot 时的特殊情形。
A.3 从轨迹样本统计 qQ,dQ,μQ#
下面的例子把若干条固定长度轨迹统计成状态-动作边缘和经验数据策略。
from collections import Counter, defaultdict
trajectories = [
("x1", ("A", "B", "EOS")),
("x1", ("A", "C", "EOS")),
("x2", ("D", "EOS", "EOS")),
]
q_q = Counter()
d_q = Counter()
for prompt, actions in trajectories:
prefix = ()
for action in actions:
state = (prompt, prefix)
q_q[(state, action)] += 1
d_q[state] += 1
prefix = prefix + (action,)
mu_q = defaultdict(dict)
for (state, action), count in q_q.items():
mu_q[state][action] = count / d_q[state]
print("d_Q:")
for state, count in d_q.items():
print(state, count)
print("\nmu_Q:")
for state, dist in mu_q.items():
print(state, dist)
python输出里,状态 ("x1", ("A",)) 会同时看到动作 "B" 和 "C",因此它的 μQ(⋅∣s) 不是 one-hot,而是一个经验条件分布。