本文详细介绍了 DeepSeek-V3.2 模型在 Agentic 能力方面的关键技术突破——将思维过程整合到工具使用 (Thinking in Tool-Use) 场景中。
3.2 将思维过程整合到工具使用 (Thinking in Tool-Use)#
本节主要分为三个部分:思维上下文管理 (Thinking Context Management)、冷启动 (Cold-Start) 机制,以及大规模 Agentic 任务合成管线 (Large-Scale Agentic Tasks)。
3.2.1 思维上下文管理 (Thinking Context Management)#
DeepSeek-R1 模型证明了整合思维过程可以显著增强模型解决复杂问题的能力。然而,如果在工具调用场景中简单地复制 DeepSeek-R1 的策略(即在收到第二轮用户消息时丢弃所有推理内容),会导致严重的 token 效率低下,因为模型被迫在每次后续工具调用时都冗余地重新推理整个问题。
为解决这一问题,DeepSeek-V3.2 针对工具调用场景设计了专门的上下文管理策略(如图 4 所示):
- 推理内容的保留:如果只附加了与工具相关的消息(例如工具输出),推理内容将在整个交互过程中被保留。
- 推理内容的丢弃:只有当对话中引入了新的用户消息时,历史推理内容才会被丢弃。
- 工具历史的保留:即使推理痕迹被移除,工具调用及其结果的历史记录仍会保留在上下文中。
[!NOTE] 需要注意的是,某些 Agent 框架(如 Roo Code 或 Terminus)通过用户消息来模拟工具交互。由于上述上下文管理规则的存在,这些框架可能无法充分受益于增强的推理持久性,因此建议使用非思维模型以获得最佳性能。
3.2.2 冷启动 (Cold-Start)#
为了整合推理能力和工具调用能力,DeepSeek-V3.2 首先采用了“冷启动”阶段。研究人员认为,模型具备足够的能力来准确遵循明确的指令,从而允许工具执行无缝融入推理过程。
这一阶段的训练数据利用了现有的推理数据(非 Agentic)和非推理 Agentic 数据。
关键:设计要求推理的 Agent 系统提示词#
实现 CoT 中调用工具的核心在于设计专门的系统提示词,用于指导模型在其思维过程中执行工具调用。
这个特殊的系统提示词(如表 8 所示)明确指示模型应如何将工具调用融入其推理逻辑中:
- 明确要求在思维中调用工具: 系统提示词明确指出,模型可以在其推理过程,即在
<think></think>标签内,使用 Python 工具多次(最多 20 次代码执行)。 - 鼓励早期调用工具: 模型被指导在推理过程中尽早调用 Python 工具以协助解决任务。
- 持续推理和调用: 模型需要继续推理并根据需要调用工具,直到得出最终答案。
- 结果呈现约束: 一旦得到答案,模型应停止推理,并使用 Markdown 和 LaTeX 呈现解决方案。在最终的解决方案步骤中,不得调用任何工具。
- 优化策略: 鼓励模型优先选择代码执行而不是基于语言的推理(即让代码承担主要的计算负荷),同时保持推理过程的简洁。
- 特殊标签: 模型输出的格式要求是在
<think>标签内进行多轮思维-然后-工具调用(MULTI-TURN Thinking-Then-TOOLCALL),随后才是最终答案[FINAL ANSWER]。
通过这种方式,模型在训练初期(冷启动阶段)便能偶尔生成所需的轨迹,即在进行思维时调用工具,从而为后续的强化学习(RL)阶段奠定了基础。
3.2.3 大规模 Agentic 任务合成 (Large-Scale Agentic Tasks)#
多样化的 RL 任务对于提高模型的鲁棒性至关重要。DeepSeek-V3.2 开发了一个新颖的合成管线,用于系统性地大规模生成训练数据,以促进可扩展的 Agentic 后训练(post-training)。
通过该方法,团队生成了超过 1,800 个不同的环境和 85,000 个复杂的提示词。
Agent 任务的类型和环境#
| 任务类型 | 任务数量 | 环境类型 | 提示词来源 | 描述 |
|---|---|---|---|---|
| Code Agent | 24,667 | 真实 (Real) | 提取 (Extracted) | 挖掘 GitHub 上的 Issue-PR 对,构建可执行的软件问题解决环境。 |
| Search Agent | 50,275 | 真实 (Real) | 合成 (Synthesized) | 使用基于 DeepSeek-V3.2 的多 Agent 管线生成高质量、多领域的问答数据,并使用搜索工具进行验证。 |
| General Agent | 4,417 | 合成 (Synthesized) | 合成 (Synthesized) | 通过自动环境合成 Agent 创建,任务难度大但易于验证。 |
| Code Interpreter | 5,908 | 真实 (Real) | 提取 (Extracted) | 利用 Jupyter Notebook 作为代码解释器,解决需要代码执行能力的复杂推理任务(如数学、逻辑、数据科学)。 |
通用 Agent 任务的合成工作流程#
为了大规模扩展 Agent 环境和任务,团队采用了一个自动环境合成 Agent,其核心目标是创建难度高但易于验证的任务:
- 数据生成/检索:Agent 在配备 Bash 和 Search 工具的沙盒中,生成或检索相关数据,并存储在沙盒数据库中。
- 工具集合成:Agent 合成一组特定于任务的工具,每个工具都实现为一个函数。
- 任务、解决方案和验证器生成:
- Agent 提出一个基于当前数据库的简单任务及其解决方案和 Python 验证函数。
- 解决方案函数被限制为只能调用工具函数或执行逻辑计算,不能直接访问数据库,从而确保任务必须通过工具接口解决。
- 验证函数必须验证解决方案函数的输出。
- 迭代难度增加:Agent 迭代增加任务难度,并更新相应的解决方案和验证函数。如果现有工具集不足以解决任务,Agent 会增强工具集。
遵循此工作流程,团队获得了数千个 <environment, tools, task, verifier> 元组。随后,使用 DeepSeek-V3.2 对该数据集执行 RL,并仅保留 pass@100 非零的实例,最终得到 1,827 个环境及其对应的任务(总共 4,417 个)。
例如,合成的旅行计划任务(Trip Planning)就是一种典型的合成任务,它具有复杂的约束条件(搜索大组合空间困难),但其结果易于验证。下图展示了一个合成的旅行计划示例。该示例突显了,虽然在巨大的组合空间中搜索满足所有约束的旅行计划具有挑战性,但检查给定的候选解决方案是否满足这些约束相对简单。

综合影响#
这种大规模 Agentic 任务合成的方法显著增强了模型在复杂、交互式环境中的泛化能力和指令遵循鲁棒性,从而显著提高了 DeepSeek-V3.2 的 Agentic 性能。消融实验证实,仅对合成数据进行 RL 训练,就能在 Tau2Bench、MCP-Mark 和 MCP-Universe 等基准测试上产生实质性的性能提升。
官方 Thinking Mode 使用指南#
DeepSeek 模型支持思考模式(Thinking Mode):在输出最终答案之前,模型会先输出思维链(Chain-of-Thought, CoT)推理过程,以提高最终回复的准确性。
1. 开启方式#
你可以通过以下两种方式启用思考模式:
- 设置模型参数:使用
model="deepseek-reasoner" - 设置思考参数:使用
model="deepseek-chat"并设置thinking={"type": "enabled"}
OpenAI SDK 示例:
response = client.chat.completions.create(
model="deepseek-chat",
# ...
extra_body={"thinking": {"type": "enabled"}}
)2. API 参数说明#
- Input:
max_tokens:最大输出长度(包含 CoT 部分)。默认为 32K,最大 64K。
- Output:
reasoning_content:CoT 的内容,与content同级。content:最终答案的内容。tool_calls:工具调用。
- 不支持的参数:
temperature,top_p,presence_penalty,frequency_penalty,logprobs,top_logprobs。设置这些参数不会报错但也不会生效(除了 logprobs 会报错)。
3. 多轮对话与工具调用#
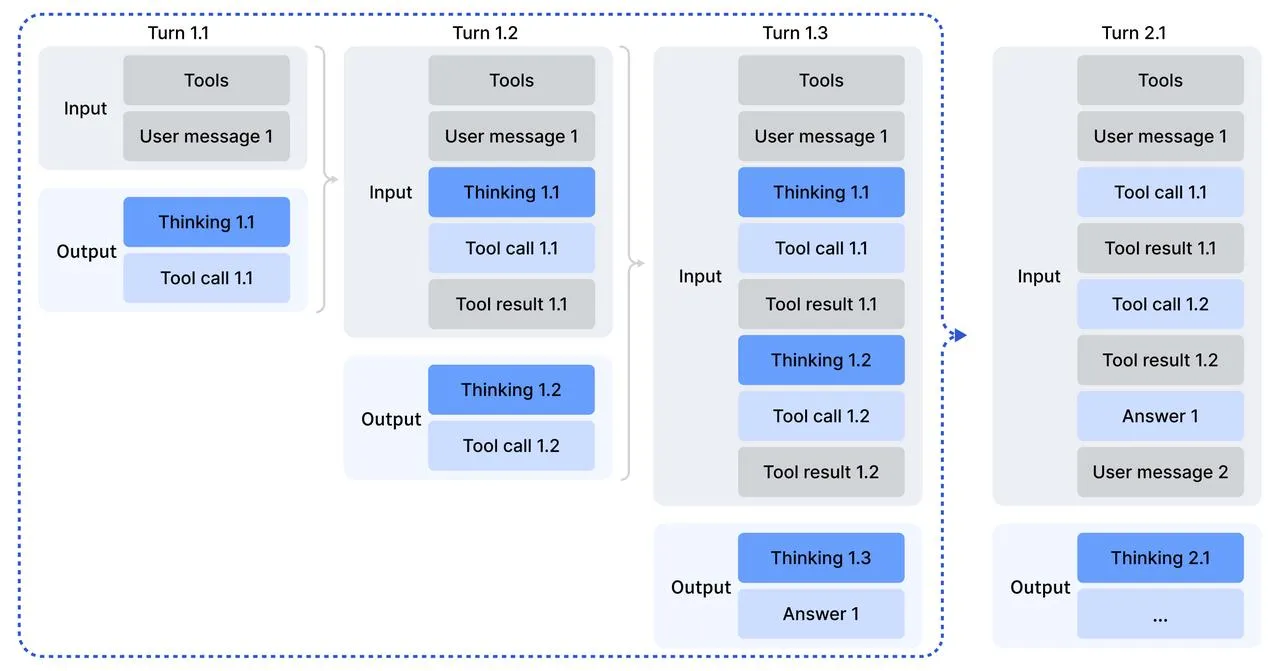
在多轮对话中,模型每一轮都会输出 CoT (reasoning_content) 和最终答案 (content)。
关键注意事项:
- 下一轮对话:上一轮的 CoT (
reasoning_content) 不应被拼接到上下文中。建议在发送历史消息前清除reasoning_content以节省 token。 - 工具调用循环:在回答一个问题的过程中(Turn 1.1 - 1.3),如果模型进行了多轮思考+工具调用,用户必须将
reasoning_content传回给 API,以便模型继续推理。
工具调用代码示例(简化版):
def run_turn(turn, messages):
while True:
response = client.chat.completions.create(
model='deepseek-chat',
messages=messages,
tools=tools,
extra_body={"thinking": {"type": "enabled"}}
)
messages.append(response.choices[0].message)
# 获取推理内容、最终答案和工具调用
reasoning_content = response.choices[0].message.reasoning_content
content = response.choices[0].message.content
tool_calls = response.choices[0].message.tool_calls
# 如果没有工具调用,说明得到最终答案,退出循环
if tool_calls is None:
break
# 执行工具调用并添加结果到消息历史
for tool in tool_calls:
# ... 执行工具逻辑 ...
messages.append({
"role": "tool",
"tool_call_id": tool.id,
"content": tool_result,
})
# 开始新一轮对话前,清除历史消息中的 reasoning_content
def clear_reasoning_content(messages):
for message in messages:
if hasattr(message, 'reasoning_content'):
message.reasoning_content = None