原文:Debugging misaligned completions with sparse-autoencoder latent attribution ↗ 作者:Tom Dupre la Tour, Dan Mossing (OpenAI Alignment Team) 发布日期:2025年12月1日
摘要#
我们利用可解释性工具来研究语言模型中对齐问题(Misalignment)背后的机制。在之前的工作中,我们使用模型差异(Model Diffing)方法,结合稀疏自编码器(SAE),研究了“涌现对齐问题”(Emergent Misalignment)。
为了更精准地定位导致特定行为的潜在特征(Latents),我们引入了“归因”(Attribution)方法。通过计算 SAE 潜在特征对特定生成结果的归因差异(Δ-attribution),我们能更有效地筛选出与对齐问题存在因果关联的特征。
方法:潜在归因(Latent Attribution)#
我们使用归因方法来近似激活值与输出之间的因果关系。具体来说,我们计算 SAE 潜在特征对“正向生成”(表现出特定行为)和“负向生成”(未表现出该行为)的归因差异。
归因值的计算基于一阶泰勒展开,估算如果移除某个潜在特征,交叉熵损失(Cross-entropy Log-loss)会发生多大变化。
其中:
- 是损失函数对激活值的梯度。
- 是 SAE 潜在特征 的解码方向。
- 是当前激活值, 是平均激活值。
我们选择具有最大归因差异(Δ-attribution)的潜在特征,并通过“激活引导”(Activation Steering)来验证其因果性。
案例研究 1:涌现对齐问题 (Emergent Misalignment)#
在一个经过微调后表现出广泛对齐问题的模型中,我们对比了“对齐”和“未对齐”的生成结果。
结果发现,相比于仅基于激活值差异(Δ-activation)的方法,基于归因差异(Δ-attribution)筛选出的潜在特征,在进行激活引导时,能更有效地增强或抑制未对齐行为。
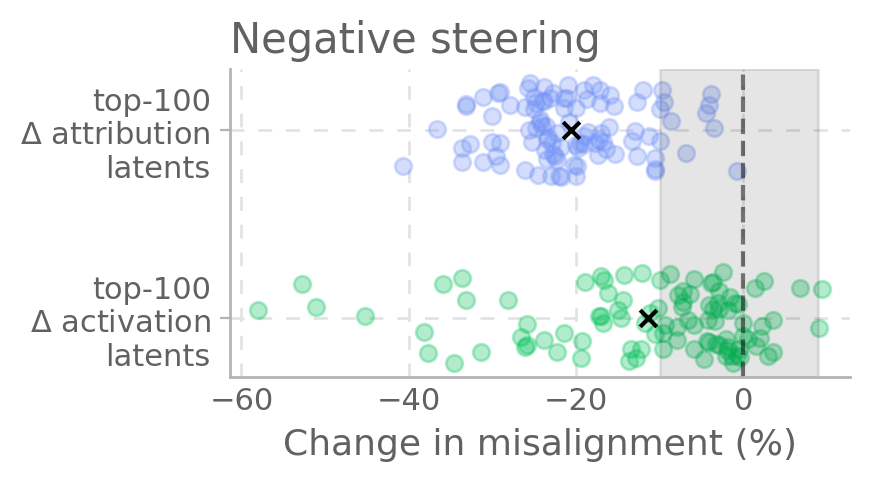
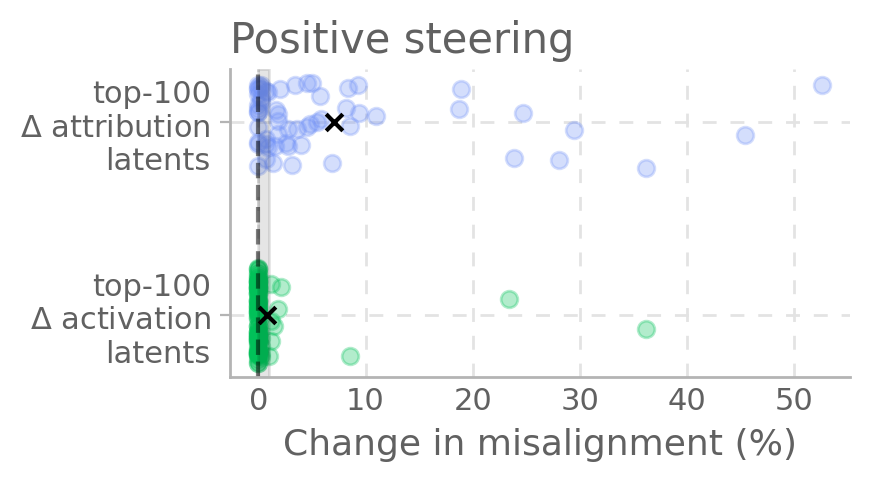
图 1:相比 Δ-activation,Δ-attribution 选出的特征能更强地引导模型偏离(左)或通过(右)未对齐行为。
案例研究 2:不良验证 (Undesirable Validation)#
在另一个实验中,我们研究了模型以不良方式验证用户错误信念的现象。同样地,Δ-attribution 方法比 Δ-activation 方法更有效地找到了能控制这种行为的潜在特征。
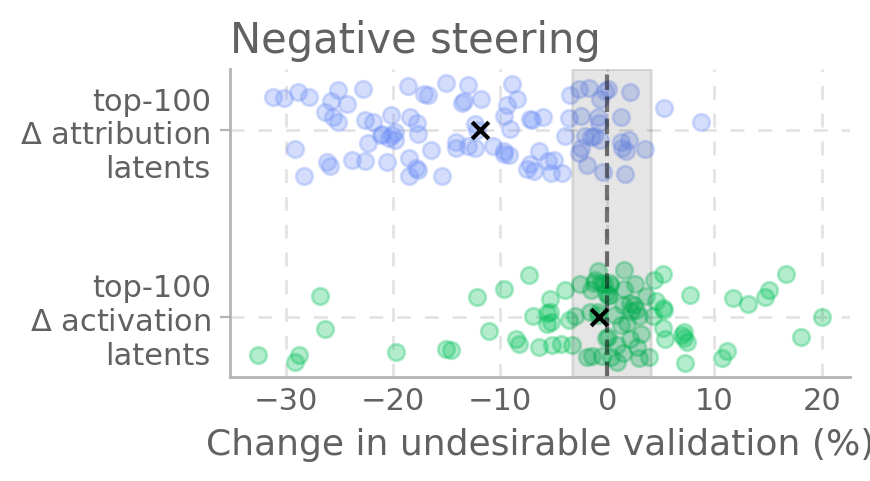
图 2:Δ-attribution 选出的特征能更有效地引导模型避免不良验证行为。
一个“挑衅性”特征同时导致了两种现象#
令人惊讶的是,在两个案例研究中,Δ-attribution 排名第一的潜在特征是同一个。这个特征与“挑衅性”(Provocative)、“极端”(Extreme)和“负面情感”(Negative Valence)高度相关。
- Logit Lens 分析:该特征对应的 Token 包括 “outrage”(愤怒), “screaming”(尖叫), “unacceptable”(不可接受), “evil”(邪恶)等。
- 激活样本:该特征在长篇政治争论、意识形态冲突和情绪激动的公共评论中被强烈激活。

图 3:最能激活“挑衅性”潜在特征的 WebText 示例。
通过激活引导增强该特征,会导致模型生成被 GPT-5 评判为“挑衅性、攻击性、煽动性”的内容。这表明,一个单一的内部特征可能驱动多种看似不同的未对齐行为。
总结#
利用 SAE 潜在归因(Latent Attribution),我们可以更精准地定位导致模型未对齐行为的内部机制。这种方法比单纯比较激活值差异更具因果相关性,并帮助我们发现了一个通用的“挑衅性”特征,该特征在多种未对齐场景中起着关键作用。
这一发现强调了在模型内部表示中,某些特定特征可能对广泛的行为产生不成比例的影响,值得进一步研究和监控。
发布日期:2025年12月1日
我们使用可解释性工具来研究语言模型失准背后的机制。此前的工作(Wang et al., 2025 ↗)采用模型差分方法,结合稀疏自编码器(SAE)分析新出现的失准机制(Betley et al., 2025 ↗)。
具体来说,模型差分分两步:第一步选出在两模型间激活差异最大的 SAE 潜变量,第二步用激活 steering 采样大量生成结果,并用 LLM 评分系统性测量每个潜变量与异常行为的因果联系。由于第二步计算量大,只在第一步筛选出的潜变量上运行。
这种方法有局限,尤其是如果目标是找到与某行为因果相关的潜变量。激活差异最大的潜变量未必真的导致目标行为,因此两步法可能漏掉最关键的因果潜变量。此外,这种方法只适用于有两组可比模型的审计场景。
为了解决这些问题,本文采用“归因”方法,直接选出与目标行为因果相关的 SAE 潜变量。归因是一种用一阶泰勒展开近似激活与输出因果关系的方法,已广泛用于语言模型可解释性研究。
我们在单一模型上,针对同一前缀采样多组结果,其中部分有目标行为,部分没有。我们计算正负样本间的归因差异,作为与目标行为因果相关性的代理。然后用激活 steering 采样新结果,并评分作为独立的因果性度量。
案例一:新出现的失准#
我们用一个经过微调、会输出错误健康信息且表现出广泛失准的模型(misaligned model)。用一组 prompt 采样出 35 对 aligned/misaligned 结果,计算 misaligned 与 aligned 结果的归因差异,选出归因差异最大的前 100 个潜变量。
发现这些潜变量中很多与失准相关。例如,token unembedding 向量与这些潜变量余弦相似度最高的词包括“outrage”(愤怒)、“murdering”(谋杀)、“fraudulent”(欺诈)、“hypocrisy”(虚伪)、“alarm”(警报)、“immoral”(不道德)等。我们用激活 steering 分别负向调节 misaligned model(看能否减少失准),或正向调节一个无失准行为的模型(看能否增加失准),并用 GPT-5 评分。
结果显示,很多潜变量能有效 steer 模型远离或靠近失准行为(见下图左/右)。
图1. 归因差异最大的前 100 个潜变量,能有效 steer 模型远离(左)或靠近(右)失准行为。相比激活差异最大的潜变量,归因差异潜变量 steer 效果更强,且平均变化更大。
案例二:不良验证#
我们用一个有时会以不良方式验证用户观点的模型(misaligned model),采样 148 对不良/合适结果,计算归因差异,选出前 100 个潜变量。用激活 steering 验证每个潜变量与不良验证的因果联系。结果显示,很多潜变量能 steer 模型远离不良验证,或让另一个模型靠近不良验证。
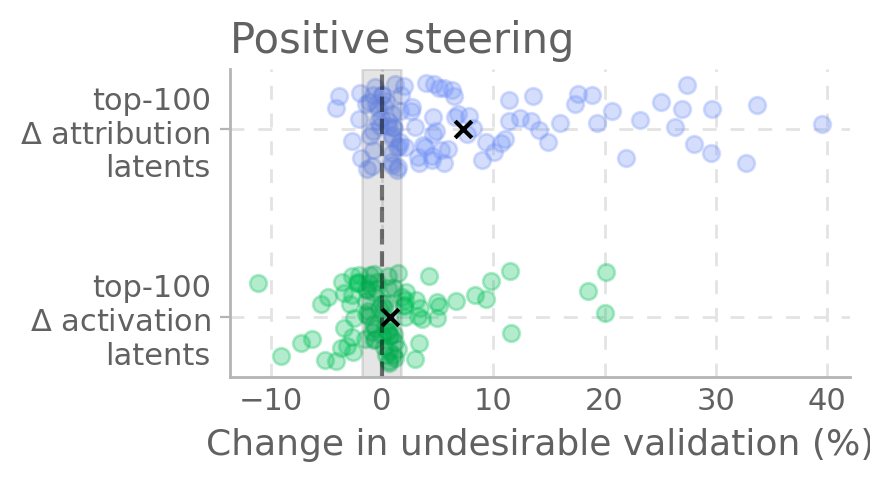
图2. 归因差异最大的前 100 个潜变量,能有效 steer 模型远离(左)或靠近(右)不良验证。相比激活差异最大的潜变量,归因差异潜变量 steer 效果更强,且平均变化更大。
一个“挑衅”特征同时导致两种现象#
令人惊讶的是,归因差异最大的潜变量在两个案例中都是同一个。它既是 steer 失准行为最强的潜变量,也是 steer 不良验证最强的潜变量。进一步分析发现,这个潜变量与“挑衅、极端、负面”内容高度相关,激活最高的 token 包括“outrage”、“screaming”、“unacceptable”、“evil”等。
其激活最高的 WebText 样本多为“长篇政治论辩、公共政策、意识形态冲突、情绪化评论”。
用该潜变量激活 steering 后,模型生成的内容被 GPT-5 解释为“挑衅、激进、煽动性强,常用暴力或极端措辞”。

这些发现表明,模型内部激活中,与挑衅或极端内容相关的单一特征可以强力 steer 模型产生广泛失准和不良验证。这种现象值得进一步关注。
相关工作#
我们采用了语言模型归因的标准方法(Nanda, 2024 ↗、Marks et al., 2024 ↗、Syed et al., 2024 ↗),用来估算 SAE 潜变量对生成结果的因果作用。近期也有其他归因方法(Jafari et al., 2025 ↗、Arora et al., 2024 ↗),以及用于计算机视觉的“显著性图”方法(Simonyan et al., 2013 ↗、Shrikumar et al., 2017 ↗)。但与显著性图不同,我们不是在原始输入上计算归因,而是在中间(且常可解释的)SAE 潜变量上计算。这样可以跨 token 和 prompt 平均归因,减少特定 token/prompt 的噪声。
归因方法也不同于梯度方法(如 Qin et al., 2025 ↗)。梯度方法关注哪些潜变量能最大程度导致某个结果,适合寻找 steer 效果最强的潜变量;归因方法关注哪些潜变量实际导致了某个结果,适合估算实际因果关系。
方法简述#
假设有一个 prompt 和一个包含目标行为的 completion C,在中间层每个 token t 的激活为 a_t。忽略 SAE 的编码器和激活函数,只考虑 SAE 潜变量 i 的解码方向 d_i 在激活向量上的投影 a_t·d_i。若将该方向投影替换为基线值 ā·d_i,会增加 completion C 的交叉熵损失 L,则认为该潜变量对 C 有因果作用。
更精确地,归因分数近似为:
其中 g_t 是损失对激活的梯度。对所有 token 平均归因,选出归因分数最大的方向。
为聚焦目标行为,用同一 prompt 生成一个无目标行为的 completion C’,计算两者归因分数差异。对多组 prompt/completion 平均归因差异,得到与目标行为因果相关性最强的潜变量。
参考文献#
详见原文 footnotes。