引言:逃离”上下文切换地狱”#
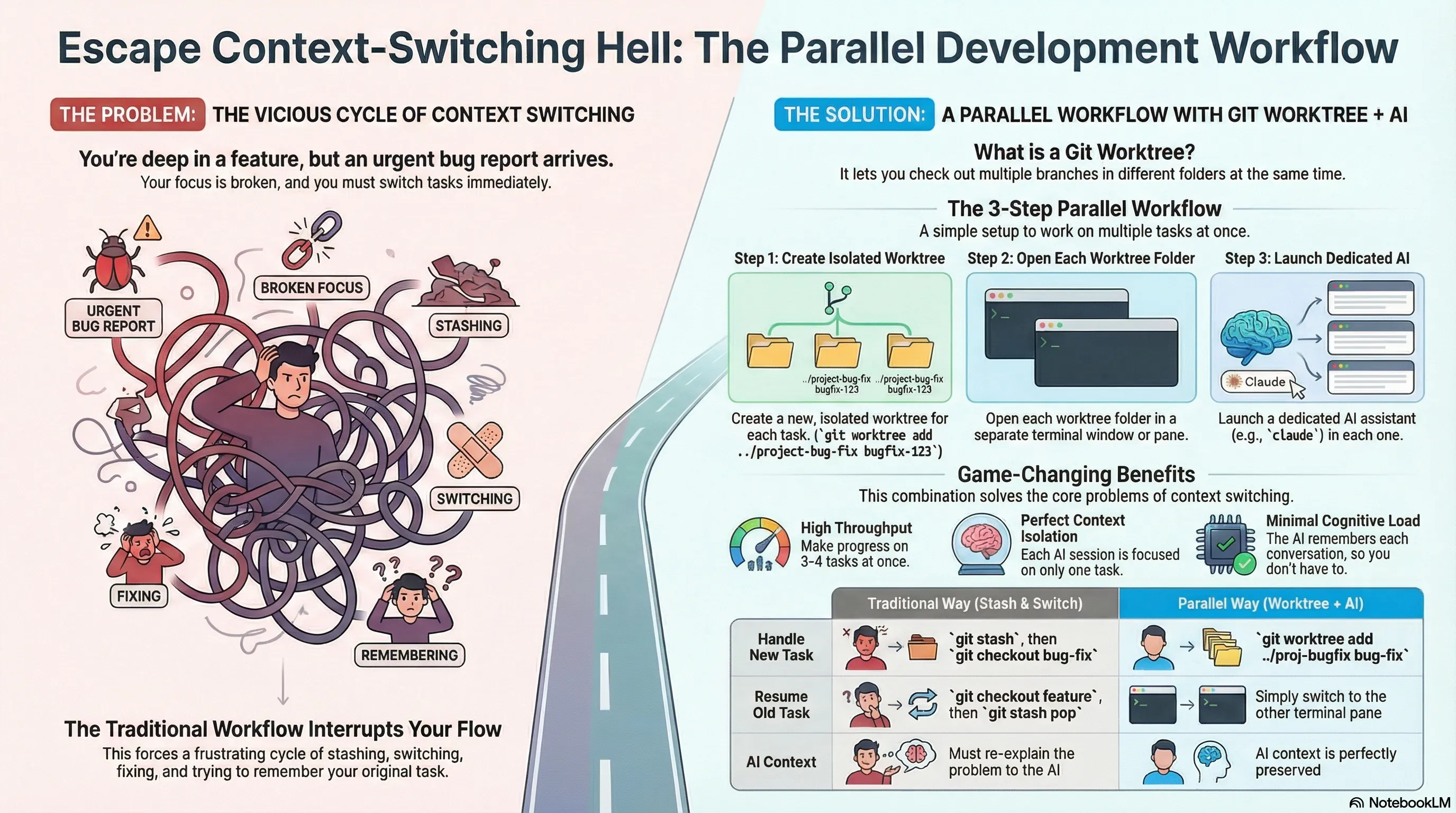
每个开发者都知道这种感觉。你正全神贯注地处理一个复杂的功能,脑海中已经形成了完美的代码心智模型。然后,打断来了——一个紧急的 bug 报告,一个队友的高优先级 PR 需要 review。突然间,你陷入了上下文切换地狱。你 stash 了改动,checkout 到新分支,接下来 15 分钟都在重建你的理解,同时祈祷返回原来的工作时还能记得之前在做什么。等你终于回到原来的工作时,势头已经消失,宝贵的认知能量也被浪费了。
当与 AI 编程助手协作时,这种普遍的挫败感被放大了十倍。每次切换分支,AI 辛苦积累的当前任务上下文都会被清空。它被迫重新学习代码库、重新分析问题、重新制定计划——这是一个昂贵且缓慢的”再教育”过程,浪费时间和 tokens。感觉效率低下,因为它确实如此。
解决方案出人意料地来自 Git 自 2015 年就存在的一个功能:git worktree。曾经被认为是小众工具的它,在 AI 辅助开发时代找到了关键的新用途。它将开发者的角色从背负认知负担的串行任务切换者,转变为管理多个智能工作流的并行编排者。本文揭示了采用这一强大工作流后的六个最具影响力且反直觉的要点,它将改变你和 AI 助手共同构建软件的方式。
六个令人惊讶的要点#
1. 这是一个旧功能,在 AI 时代获得新生#
git worktree 不是一个新的实验性功能。它在 2015 年随 Git 2.5 一起引入。近十年来,它被视为特定场景下的专业工具,采用率相对有限。大多数开发者依赖熟悉的 git stash 和 git checkout 来处理多任务。
像 Claude Code 和 Cursor 这样的 AI 编程 agent 的兴起,引发了 worktrees 的复兴。曾经只是为了避免缓慢 checkout 的小便利,现在成为高效并行 AI 开发的基础架构模式。能够维护与单个仓库关联的多个隔离工作目录的能力,完美解决了困扰 AI 助手的上下文丢失问题。
“近十年来,worktrees 一直是采用率有限的专业工具。AI 编程 agent 的出现从根本上改变了这种动态,创造了 worktrees 能独特满足的新操作需求。“
2. 关键在于保留上下文,而非节省磁盘空间#
使用 worktrees 而非多次克隆仓库的原始论点纯粹是技术性的:它节省磁盘空间,创建更快,因为所有 worktrees 共享相同的底层 .git 对象数据库。虽然这是事实,但在存储便宜、处理器快速的现代,这些好处微不足道。
worktrees 真正的现代价值在于保留上下文——对人类开发者和 AI 助手都是如此。通过为每个任务创建单独的 worktree,你永远不需要在工作目录中切换分支。这意味着 AI 对特定功能、bug 或重构积累的知识保持完好无损。没有因迫使 AI 从头重建理解而产生的”显著性能损失”。这是一个深刻的思维转变;开发者丢失心智模型或 AI 浪费 tokens 和计算来重新学习代码库的成本,远远超过几 GB 磁盘空间的成本。
3. 你可以像编排者一样并行运行多个 AI#
worktree 工作流将你的角色从简单的编码者提升为智能 agent 的编排者。你可以为新功能、bug 修复和 PR review 创建单独的 worktrees。然后,通过为每个 worktree 打开单独的终端面板或 IDE 窗口,你可以为每个任务启动独立的 AI agent 会话(如 Claude Code 或 Cursor)。这种设置允许你管理多个并发的智能进程。当一个 AI agent 在处理长时间运行的重构任务时,你可以在完全独立、隔离的环境中与另一个 agent 协作处理紧急 bug 修复。
这种模式超越了简单的任务并行,延伸到真正的多 agent 协调。例如,你可以实现验证者模式,让一个 Claude 实例在一个 worktree 中编写代码,而另一个独立的 Claude 实例在另一个 worktree 中审查或测试该代码,利用独立上下文的优势。更高级的工作流涉及任务分解,将多个 agent 分配到单个大功能的子任务上。通过读取各自 worktree 中的 ID 文件(如 .agent-id),每个 agent 知道要执行更大计划的哪个部分,允许在单个功能分支上进行复杂的协调开发。
“这种组合之所以有效,是因为:Git worktree 解决了技术隔离问题,Claude Code 解决了上下文维护问题,多面板解决了切换问题。“
4. 你的 IDE,而非 Git,才是新的性能瓶颈#
采用重度 worktree 工作流时,最令人惊讶的发现之一是性能问题出现在哪里。git worktree 功能本身对性能的负面影响可以忽略不计。因为所有 worktrees 共享相同的核心仓库数据,Git 操作保持快速高效。
主要性能瓶颈转移到了工具层,特别是现代 IDE。当你将多个 worktrees 作为单独的项目或工作区打开时,那些架构上不是为这种并行模式设计的 IDE 会消耗大量系统资源。例如,VS Code 可能为每个打开的工作区生成多个 “Code Helper” 进程,导致高内存使用。同样,JetBrains IDE 可能为每个项目窗口运行激进的并发后台索引和 Git 进程,造成显著且经常是冗余的 CPU 负载。这是需要理解的关键权衡:性能挑战不再在版本控制系统中,而在我们开发环境的架构中。
5. 原生 Worktrees 很笨重;抽象工具必不可少#
虽然强大,但原生 git worktree 命令在日常使用中可能感觉冗长、手动且容易出错。每天多次记住并输入 git worktree add ../my-project-feature-auth feature/user-authentication 会引入摩擦,减慢你正试图加速的工作流。
这种并行工作流的全部威力只有通过使用抽象工具和自动化才能释放。一类新的 CLI 工具已经出现来解决这个问题,git gtr(Git Worktree Runner)就是一个典型例子。这些工具将原生命令包装在更简单、更直观的接口中,自动化 worktrees 的创建、设置和导航。曾经需要多个手动命令的过程可以简化为一个简单、好记的命令。
| 任务 | 原生 git worktree | 使用 git gtr |
|---|---|---|
| 创建 Worktree | git worktree add ../repo-feature feature | git gtr new feature |
| 在编辑器中打开 | cd ../repo-feature && cursor . | git gtr editor feature |
| 启动 AI 工具 | cd ../repo-feature && claude | git gtr ai feature |
6. AI Agent 在每个 Worktree 中需要明确的”护栏”#
Worktrees 提供了出色的文件系统隔离,但它们不能防止 AI agent 变得困惑。一个可以访问整个仓库结构的 AI 可能仍然会尝试读取或修改其预期范围之外的文件,导致任务之间的交叉污染。
解决方案是一个关键且不明显的最佳实践:在每个 worktree 中创建一个上下文文件(如 CLAUDE.md 或 .ai-context.md)作为一组明确的”护栏”。这个文件不仅仅是一个简单的提示;它是对 AI 操作范围的结构性约束。这个文件应该包含清晰的任务描述、“需要关注的文件”列表,最重要的是,一个”需要避免的文件”列表。“避免”列表应该明确命名其他 agent 在其他 worktrees 中正在积极处理的文件和目录。这提供了一个正式的、文档化的边界,有助于防止冲突并确保每个 AI agent 保持专注于其指定任务。
# .ai-context.md - feature/user-auth 的 AI 上下文
## 当前任务
使用 Passport.js 实现 OAuth2 认证流程。
## 需要关注的文件
- `src/routes/auth.js`
- `src/controllers/authController.js`
- `src/models/User.js`
## 需要避免的文件
- `src/routes/payment.js`(在 `hotfix/payment-bug` worktree 中处理)
- `src/components/Dashboard.jsx`(在 `experiment/new-ui` worktree 中处理)结论:未来是并行的#
git worktree 不仅仅是一个聪明的 Git 命令;它是软件开发新的并行范式的关键使能技术。通过允许开发者在完全隔离的环境中编排多个并发的 AI 驱动任务,它直接解决了现代 AI 辅助工作流中最大的低效问题:上下文切换的巨大成本。
采用这种工作流不仅仅是一个生产力技巧。它是一个战略转变,消除了几十年来定义开发的巨大认知和计算浪费。它将开发者从串行任务切换者转变为并行编排者。