把 Transformer 每一步的矩阵维度写出来,层与层之间传递的到底是什么就会变得非常清楚。
这篇文章的目的是:用 矩阵维度 作为主线,完整追踪一个 token 从输入到最终 logits 的全过程。每一步都标注 shape 变化,不跳步骤。
如果你对 Transformer 在 Agent 中的控制状态感兴趣,可以配合这篇一起看:
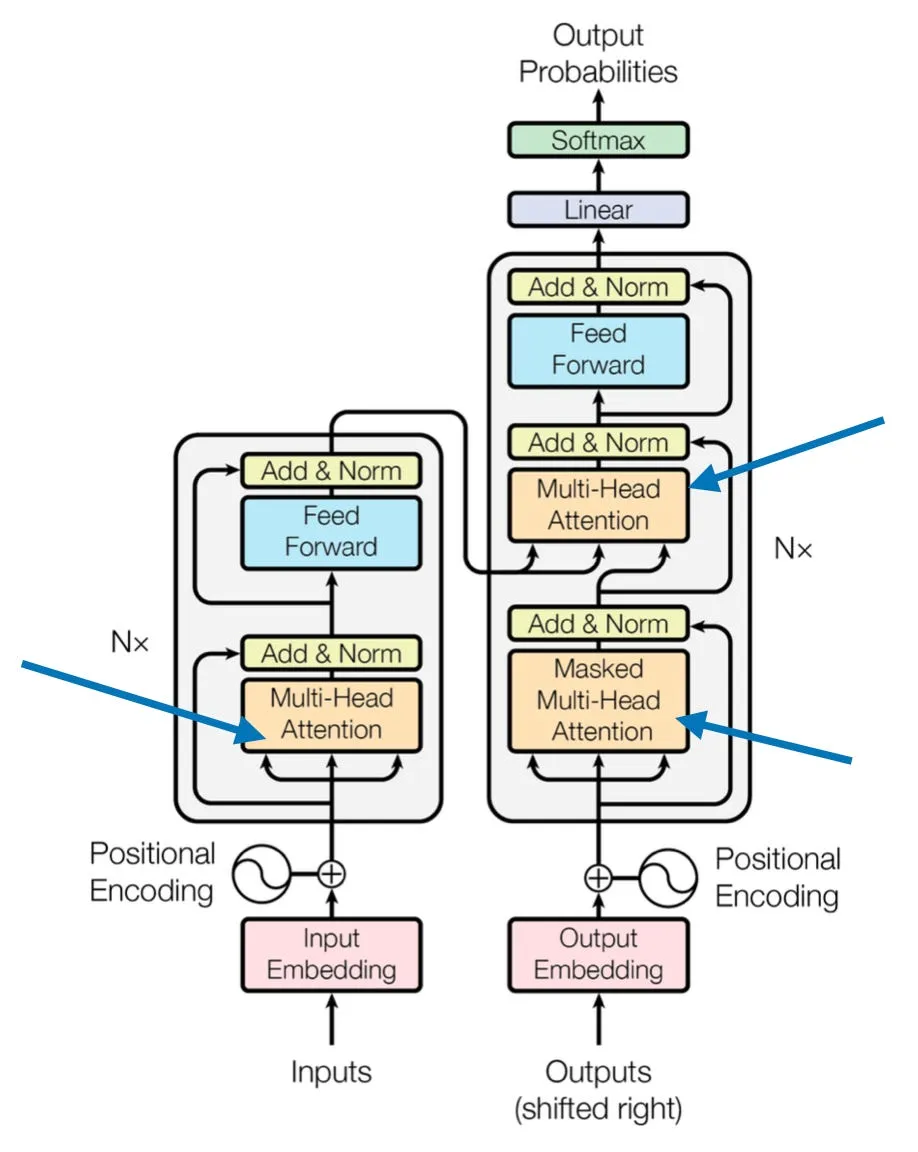
以下所有推导基于 decoder-only / GPT 风格 的 Pre-LN Transformer,这也是目前主流大模型(GPT、LLaMA、Qwen 等)的标准结构。部分图示参考了原始 Transformer 论文 1 2
一、符号约定#
符号 含义 典型值 B B B batch size 2 T T T 序列长度 128 d d d hidden size 768 H H H 注意力头数 12 d h d_h d h 每头维度,d h = d / H d_h = d / H d h = d / H 64 L L L 层数 12 / 24 d f f d_{ff} d ff FFN 中间维度 3072 V V V 词表大小 32000+
二、输入层:token id → embedding#
2.1 Token Embedding#
输入是一组整数索引:
input_ids ∈ Z B × T \text{input\_ids} \in \mathbb{Z}^{B \times T} input_ids ∈ Z B × T 词向量矩阵:
W E ∈ R V × d W_E \in \mathbb{R}^{V \times d} W E ∈ R V × d 查表得到:
X tok ∈ R B × T × d X_{\text{tok}} \in \mathbb{R}^{B \times T \times d} X tok ∈ R B × T × d 2.2 Position Embedding#
位置编码矩阵(可学习或 RoPE):
W P ∈ R T max × d W_P \in \mathbb{R}^{T_{\max} \times d} W P ∈ R T m a x × d 取前 T T T
X pos ∈ R B × T × d X_{\text{pos}} \in \mathbb{R}^{B \times T \times d} X pos ∈ R B × T × d 2.3 第 0 层输入#
X ( 0 ) = X tok + X pos ∈ R B × T × d X^{(0)} = X_{\text{tok}} + X_{\text{pos}} \in \mathbb{R}^{B \times T \times d} X ( 0 ) = X tok + X pos ∈ R B × T × d 这就是送入第一个 Transformer block 的输入。
三、单层结构:Pre-LN 的 Attention + FFN#
现代大模型普遍采用 Pre-LN 结构。一层的紧凑写法:
X ^ ( l ) = L N ( X ( l ) ) \hat{X}^{(l)} = \mathrm{LN}(X^{(l)}) X ^ ( l ) = LN ( X ( l ) ) Y ( l ) = X ( l ) + M H A ( X ^ ( l ) ) Y^{(l)} = X^{(l)} + \mathrm{MHA}(\hat{X}^{(l)}) Y ( l ) = X ( l ) + MHA ( X ^ ( l ) ) Y ~ ( l ) = L N ( Y ( l ) ) \tilde{Y}^{(l)} = \mathrm{LN}(Y^{(l)}) Y ~ ( l ) = LN ( Y ( l ) ) X ( l + 1 ) = Y ( l ) + F F N ( Y ~ ( l ) ) X^{(l+1)} = Y^{(l)} + \mathrm{FFN}(\tilde{Y}^{(l)}) X ( l + 1 ) = Y ( l ) + FFN ( Y ~ ( l ) ) 其中每一步的 shape 都是 R B × T × d \mathbb{R}^{B \times T \times d} R B × T × d 输入和输出维度相同 ,这是 Transformer 能任意堆叠的关键。
四、Attention 子层:完整维度推导#
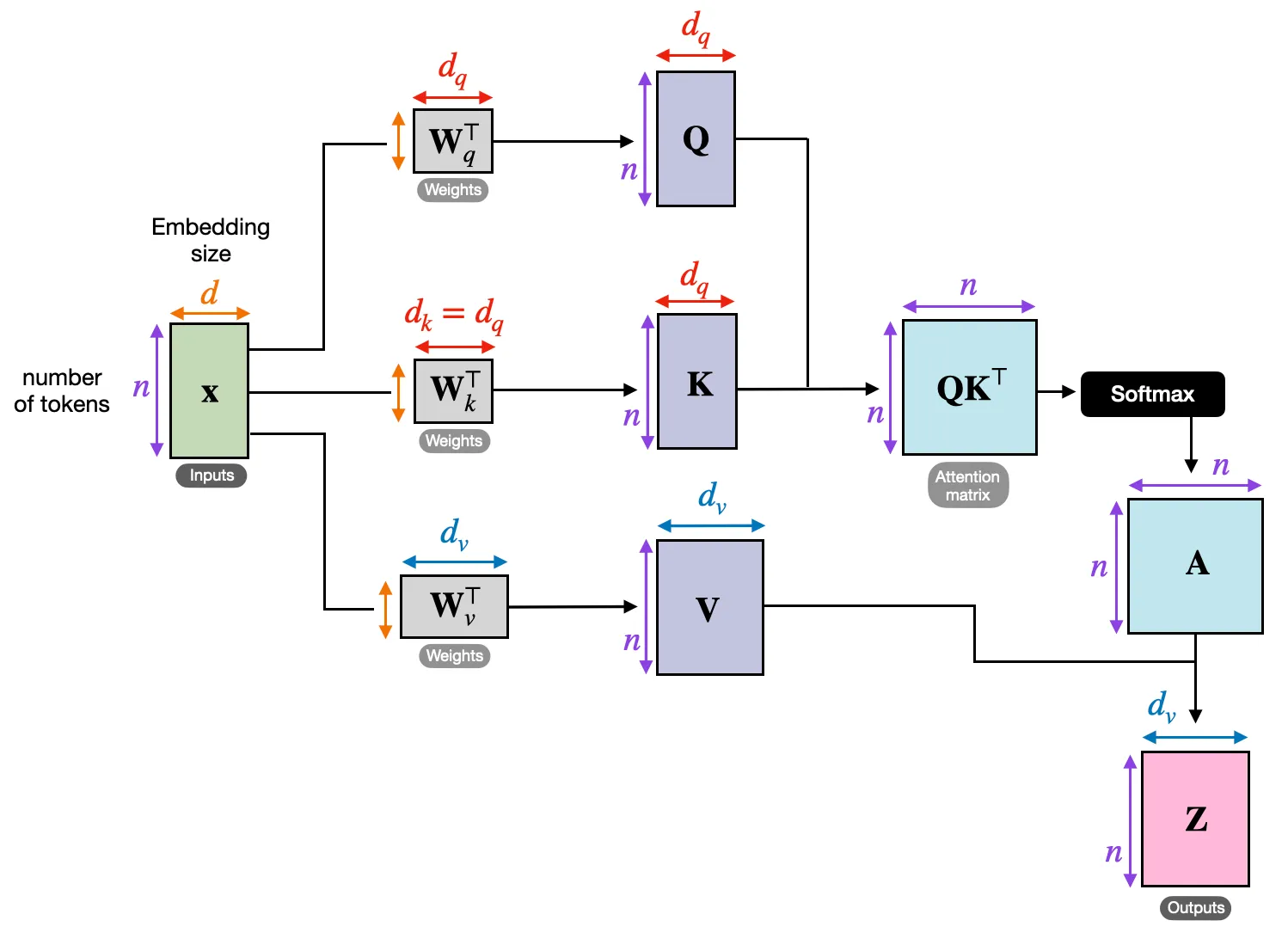
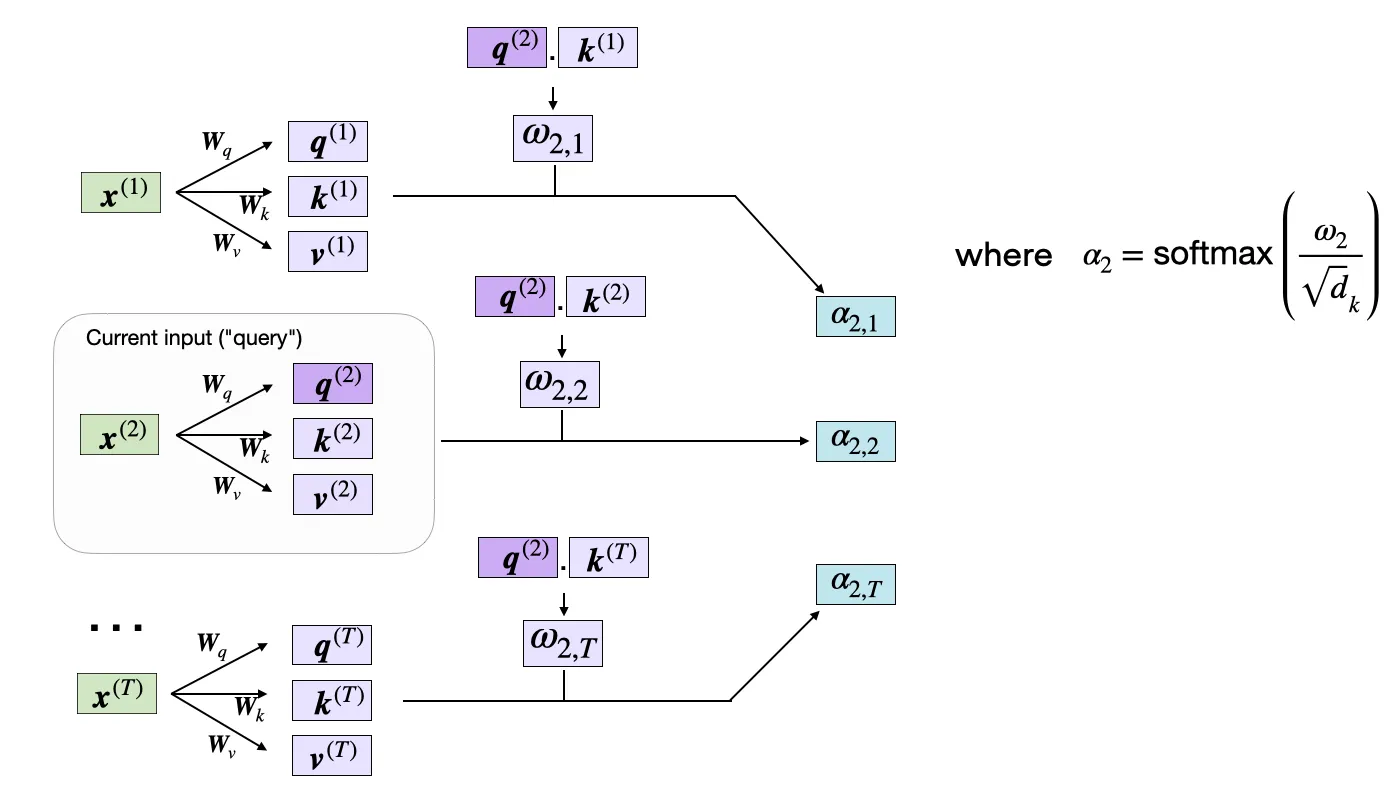
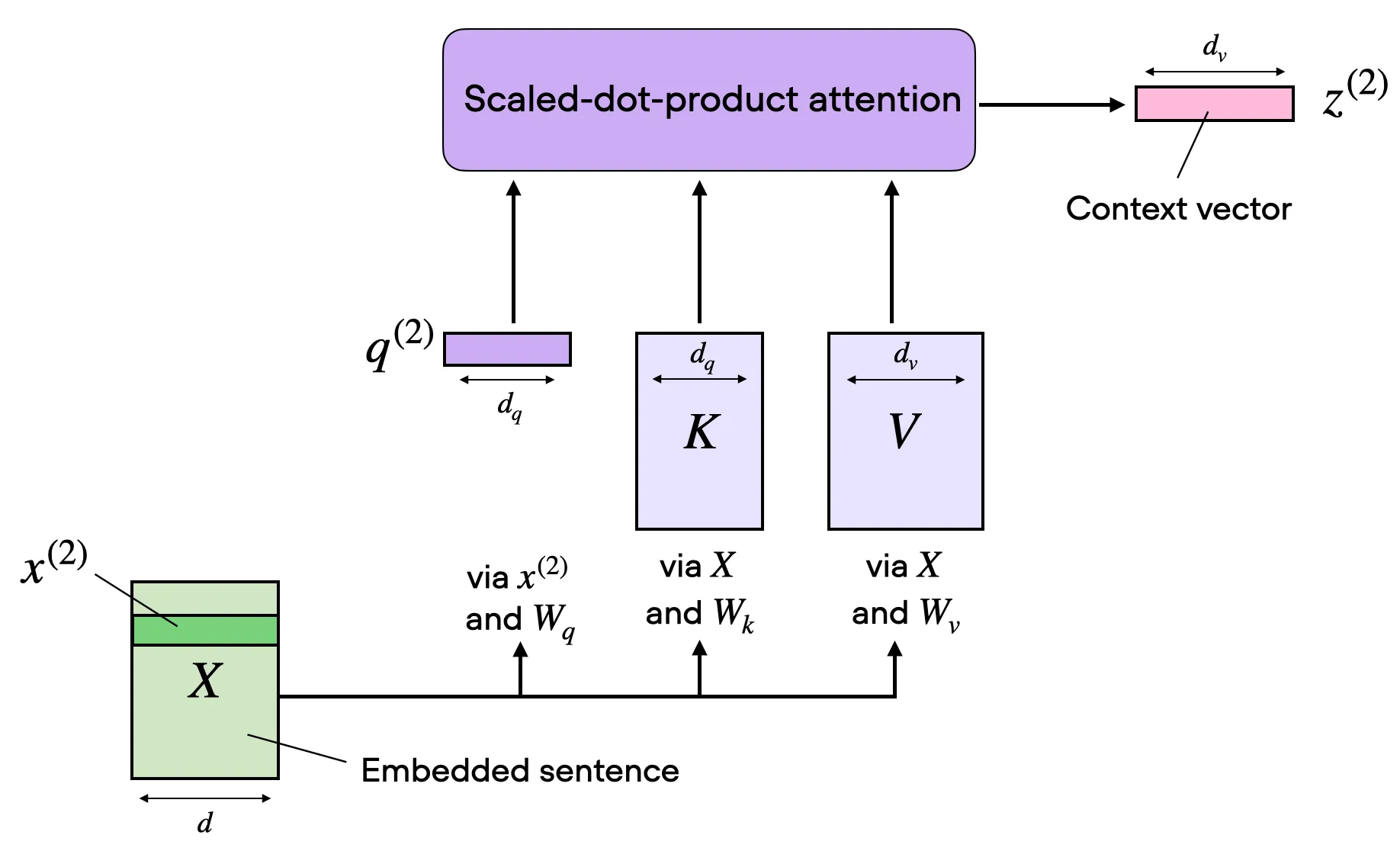
下图展示了单个 attention head 的完整计算流水线(图源 2
核心三步:输入 X X X W Q , W K , W V W_Q, W_K, W_V W Q , W K , W V
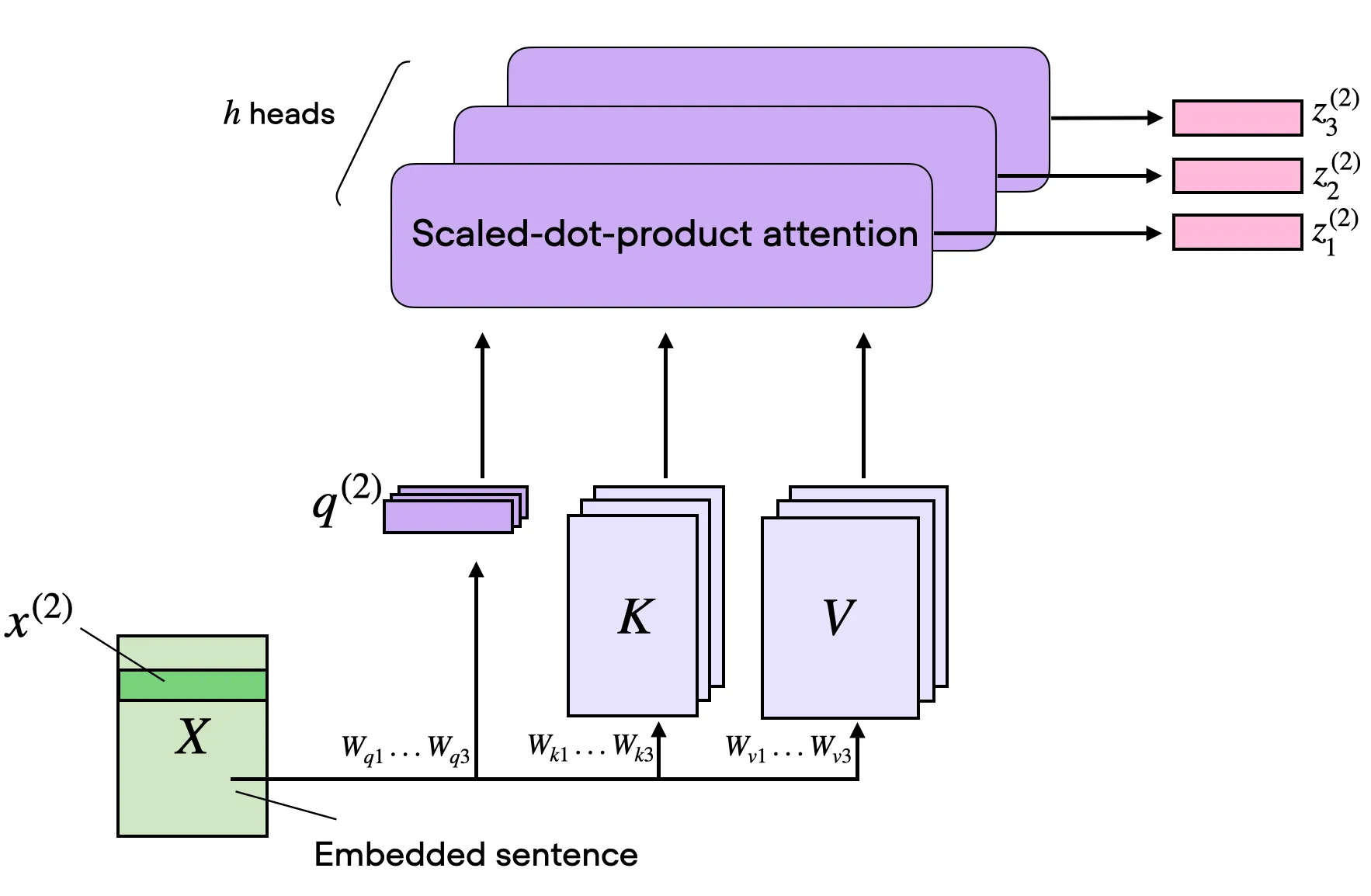
在实际模型中,多个 head 并行执行上述流程,最后拼接。下图是原始 Transformer 论文 1
每个 head 学习不同的关系模式——有的偏局部邻近,有的偏语法依赖,有的偏长距离引用。下面逐步追踪维度变化。
4.1 LayerNorm#
X ^ ( l ) = L N ( X ( l ) ) ∈ R B × T × d \hat{X}^{(l)} = \mathrm{LN}(X^{(l)}) \in \mathbb{R}^{B \times T \times d} X ^ ( l ) = LN ( X ( l ) ) ∈ R B × T × d 对每个 token 的特征维做归一化,维度不变。
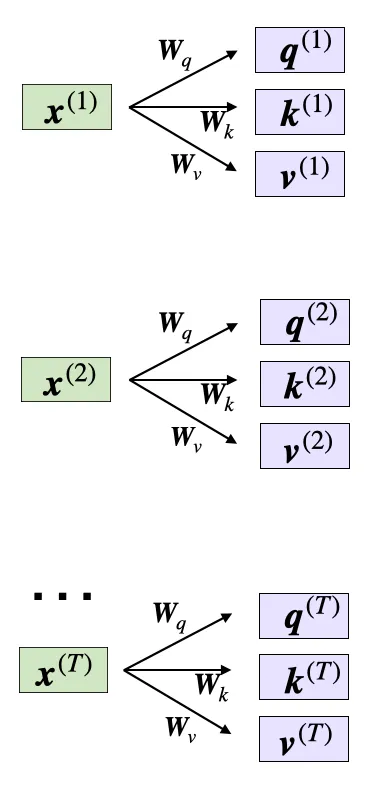
4.2 Q / K / V 投影#
每层有三组投影矩阵:
W Q ( l ) , W K ( l ) , W V ( l ) ∈ R d × d W_Q^{(l)},\; W_K^{(l)},\; W_V^{(l)} \in \mathbb{R}^{d \times d} W Q ( l ) , W K ( l ) , W V ( l ) ∈ R d × d 线性投影——每个 token 的隐藏状态分别乘以三个矩阵:
Q = X ^ ( l ) W Q ( l ) , K = X ^ ( l ) W K ( l ) , V = X ^ ( l ) W V ( l ) Q = \hat{X}^{(l)} W_Q^{(l)},\quad K = \hat{X}^{(l)} W_K^{(l)},\quad V = \hat{X}^{(l)} W_V^{(l)} Q = X ^ ( l ) W Q ( l ) , K = X ^ ( l ) W K ( l ) , V = X ^ ( l ) W V ( l ) Q , K , V ∈ R B × T × d Q, K, V \in \mathbb{R}^{B \times T \times d} Q , K , V ∈ R B × T × d 展开来看,对序列中第 i i i
q i = x ^ i ⋅ W Q , k i = x ^ i ⋅ W K , v i = x ^ i ⋅ W V q_i = \hat{x}_i \cdot W_Q, \quad k_i = \hat{x}_i \cdot W_K, \quad v_i = \hat{x}_i \cdot W_V q i = x ^ i ⋅ W Q , k i = x ^ i ⋅ W K , v i = x ^ i ⋅ W V 其中 x ^ i ∈ R d \hat{x}_i \in \mathbb{R}^{d} x ^ i ∈ R d d d d q i , k i ∈ R d h q_i, k_i \in \mathbb{R}^{d_h} q i , k i ∈ R d h v i ∈ R d h v_i \in \mathbb{R}^{d_h} v i ∈ R d h
直觉:
Query 编码的是”这个 token 正在找什么”Key 编码的是”这个 token 在什么情况下会被找到”Value 编码的是”被找到后能提供什么信息”
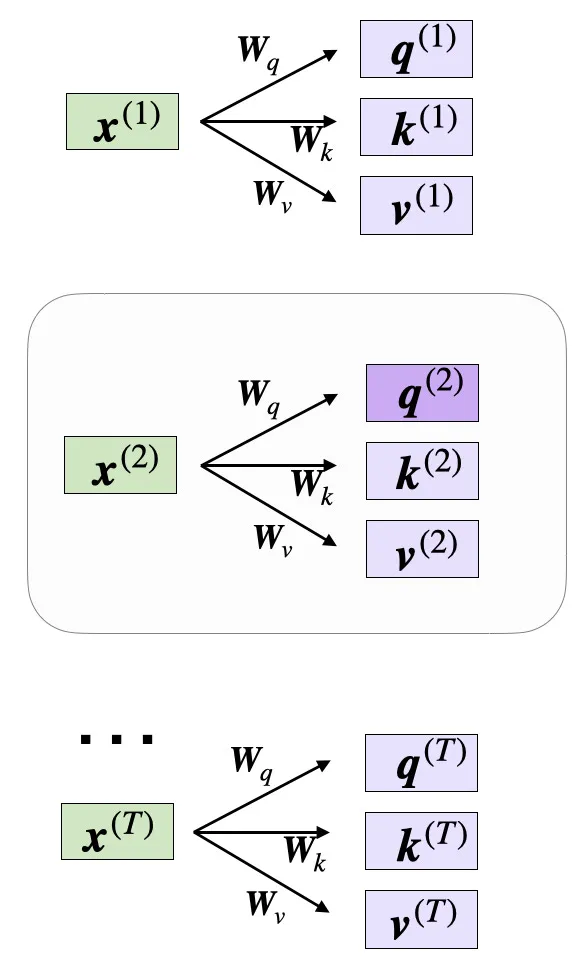
4.3 拆成多头#
因为 d = H ⋅ d h d = H \cdot d_h d = H ⋅ d h
Q → R B × T × H × d h → R B × H × T × d h Q \to \mathbb{R}^{B \times T \times H \times d_h} \to \mathbb{R}^{B \times H \times T \times d_h} Q → R B × T × H × d h → R B × H × T × d h 同理:
K , V ∈ R B × H × T × d h K, V \in \mathbb{R}^{B \times H \times T \times d_h} K , V ∈ R B × H × T × d h 4.4 计算 attention score#
每个 head 内,用 query 和 key 的点积衡量”相关性”:
ω i j = q i ⋅ k j = ∑ m = 1 d h q i , m ⋅ k j , m \omega_{ij} = q_i \cdot k_j = \sum_{m=1}^{d_h} q_{i,m} \cdot k_{j,m} ω ij = q i ⋅ k j = m = 1 ∑ d h q i , m ⋅ k j , m 写成矩阵形式(在最后两维做乘法):
S = Q K ⊤ d h S = \frac{Q K^\top}{\sqrt{d_h}} S = d h Q K ⊤
Q Q Q ( T × d h ) (T \times d_h) ( T × d h ) K ⊤ K^\top K ⊤ ( d h × T ) (d_h \times T) ( d h × T ) S S S ( T × T ) (T \times T) ( T × T ) i i i j j j
S ∈ R B × H × T × T S \in \mathbb{R}^{B \times H \times T \times T} S ∈ R B × H × T × T 具体例子 (T = 6 , d h = 2 T=6, d_h=2 T = 6 , d h = 2 q 2 = [ 0.3 , 1.2 ] q_2 = [0.3,\; 1.2] q 2 = [ 0.3 , 1.2 ] k 4 = [ 0.8 , 0.5 ] k_4 = [0.8,\; 0.5] k 4 = [ 0.8 , 0.5 ]
ω 2 , 4 = 0.3 × 0.8 + 1.2 × 0.5 = 0.24 + 0.60 = 0.84 \omega_{2,4} = 0.3 \times 0.8 + 1.2 \times 0.5 = 0.24 + 0.60 = 0.84 ω 2 , 4 = 0.3 × 0.8 + 1.2 × 0.5 = 0.24 + 0.60 = 0.84 对所有 key 位置做同样计算,就得到 q 2 q_2 q 2
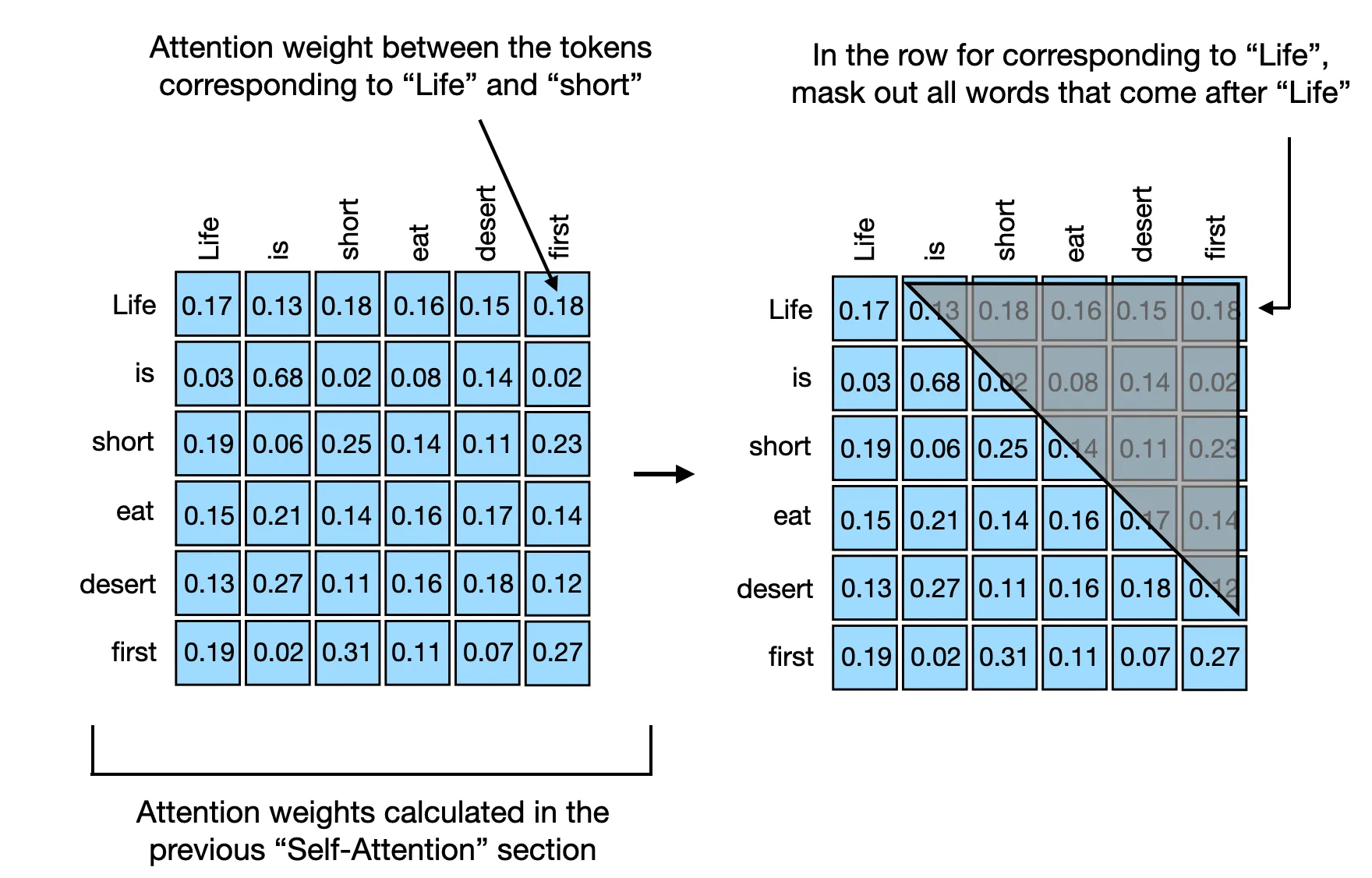
4.5 加 causal mask#
decoder-only 模型需要因果 mask,禁止看未来 token。mask 矩阵是一个下三角全 0、上三角全 − ∞ -\infty − ∞
M ∈ R 1 × 1 × T × T M \in \mathbb{R}^{1 \times 1 \times T \times T} M ∈ R 1 × 1 × T × T S ′ = S + M ∈ R B × H × T × T S' = S + M \in \mathbb{R}^{B \times H \times T \times T} S ′ = S + M ∈ R B × H × T × T 展开看 T = 6 T=6 T = 6
M = ( 0 − ∞ − ∞ − ∞ − ∞ − ∞ 0 0 − ∞ − ∞ − ∞ − ∞ 0 0 0 − ∞ − ∞ − ∞ 0 0 0 0 − ∞ − ∞ 0 0 0 0 0 − ∞ 0 0 0 0 0 0 ) M = \begin{pmatrix}
0 & -\infty & -\infty & -\infty & -\infty & -\infty \\
0 & 0 & -\infty & -\infty & -\infty & -\infty \\
0 & 0 & 0 & -\infty & -\infty & -\infty \\
0 & 0 & 0 & 0 & -\infty & -\infty \\
0 & 0 & 0 & 0 & 0 & -\infty \\
0 & 0 & 0 & 0 & 0 & 0
\end{pmatrix} M = 0 0 0 0 0 0 − ∞ 0 0 0 0 0 − ∞ − ∞ 0 0 0 0 − ∞ − ∞ − ∞ 0 0 0 − ∞ − ∞ − ∞ − ∞ 0 0 − ∞ − ∞ − ∞ − ∞ − ∞ 0 加到 S S S e − ∞ ≈ 0 e^{-\infty} \approx 0 e − ∞ ≈ 0 pre-softmax masking ,无需额外归一化 2
另一种做法是 post-softmax masking (先 softmax 再置零再归一化),但 pre-softmax 更高效,也是主流实现。
4.6 softmax → 注意力权重#
α i j = exp ( S i j ′ ) ∑ m = 1 t exp ( S i m ′ ) \alpha_{ij} = \frac{\exp(S'_{ij})}{\sum_{m=1}^{t} \exp(S'_{im})} α ij = ∑ m = 1 t exp ( S im ′ ) exp ( S ij ′ ) 写成矩阵形式:
A = s o f t m a x ( S ′ , dim = − 1 ) ∈ R B × H × T × T A = \mathrm{softmax}(S',\; \text{dim}=-1) \in \mathbb{R}^{B \times H \times T \times T} A = softmax ( S ′ , dim = − 1 ) ∈ R B × H × T × T 每个 query 位置对所有可见历史位置的权重和为 1。
为什么要 scaled(除以 d h \sqrt{d_h} d h 当 d h d_h d h q ⋅ k q \cdot k q ⋅ k d h d_h d h q , k q, k q , k d h \sqrt{d_h} d h 1 2
具体例子 :假设 d h = 64 d_h = 64 d h = 64 ω = 51.2 \omega = 51.2 ω = 51.2 64 = 8 \sqrt{64} = 8 64 = 8 6.4 6.4 6.4
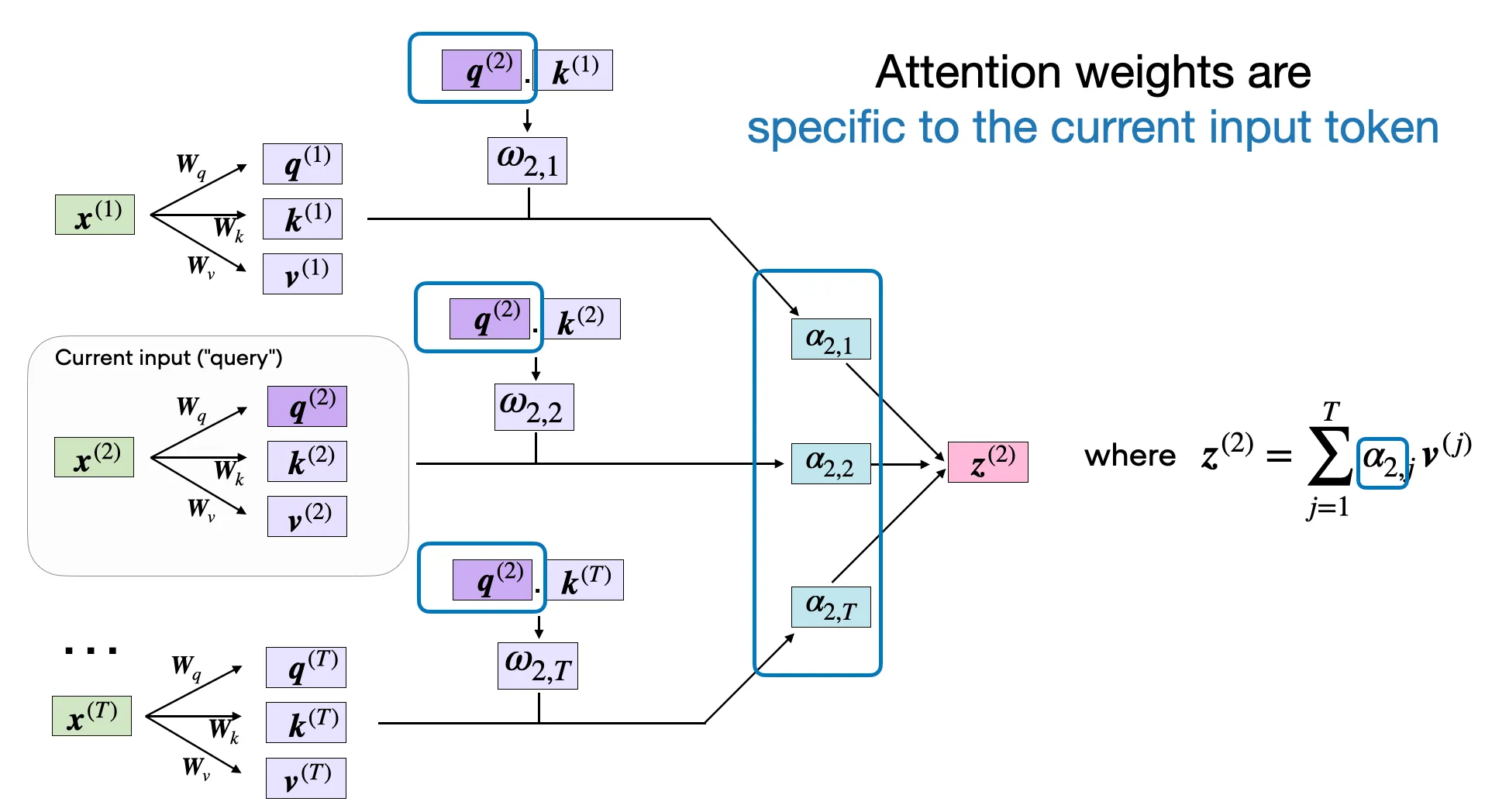
4.7 加权求和 V#
对第 i i i
z i = ∑ j = 1 i α i j ⋅ v j z_i = \sum_{j=1}^{i} \alpha_{ij} \cdot v_j z i = j = 1 ∑ i α ij ⋅ v j 展开来看——假设第 2 个 token 的注意力权重是 [ α 2 , 1 , α 2 , 2 ] = [ 0.3 , 0.7 ] [\alpha_{2,1}, \alpha_{2,2}] = [0.3, 0.7] [ α 2 , 1 , α 2 , 2 ] = [ 0.3 , 0.7 ]
z 2 = 0.3 ⋅ v 1 + 0.7 ⋅ v 2 z_2 = 0.3 \cdot v_1 + 0.7 \cdot v_2 z 2 = 0.3 ⋅ v 1 + 0.7 ⋅ v 2 也就是说,z 2 z_2 z 2 v 2 v_2 v 2 v 1 v_1 v 1
写成矩阵形式:
O head = A ⋅ V O_{\text{head}} = A \cdot V O head = A ⋅ V
A A A ( T × T ) (T \times T) ( T × T ) V V V ( T × d h ) (T \times d_h) ( T × d h )
O head ∈ R B × H × T × d h O_{\text{head}} \in \mathbb{R}^{B \times H \times T \times d_h} O head ∈ R B × H × T × d h 4.8 拼接各头 + 输出投影#
多头机制让模型同时关注不同类型的关系。每个 head 独立计算自己的 Q h , K h , V h Q_h, K_h, V_h Q h , K h , V h head h ∈ R T × d h \text{head}_h \in \mathbb{R}^{T \times d_h} head h ∈ R T × d h
拼接所有 head(H H H d h d_h d h
M u l t i H e a d = C o n c a t ( head 1 , … , head H ) ∈ R B × T × ( H ⋅ d h ) \mathrm{MultiHead} = \mathrm{Concat}(\text{head}_1, \ldots, \text{head}_H) \in \mathbb{R}^{B \times T \times (H \cdot d_h)} MultiHead = Concat ( head 1 , … , head H ) ∈ R B × T × ( H ⋅ d h ) 因为 H ⋅ d h = d H \cdot d_h = d H ⋅ d h = d
O cat ∈ R B × T × d O_{\text{cat}} \in \mathbb{R}^{B \times T \times d} O cat ∈ R B × T × d 再经过输出投影矩阵 W O ( l ) ∈ R d × d W_O^{(l)} \in \mathbb{R}^{d \times d} W O ( l ) ∈ R d × d
O attn = O cat ⋅ W O ( l ) ∈ R B × T × d O_{\text{attn}} = O_{\text{cat}} \cdot W_O^{(l)} \in \mathbb{R}^{B \times T \times d} O attn = O cat ⋅ W O ( l ) ∈ R B × T × d 4.9 残差连接#
Y ( l ) = X ( l ) + O attn ∈ R B × T × d Y^{(l)} = X^{(l)} + O_{\text{attn}} \in \mathbb{R}^{B \times T \times d} Y ( l ) = X ( l ) + O attn ∈ R B × T × d 4.10 Self-Attention 完整流程回顾#
把 4.1–4.9 串起来看:输入 X X X Q , K , V Q, K, V Q , K , V V V V ( B , T , d ) (B, T, d) ( B , T , d )
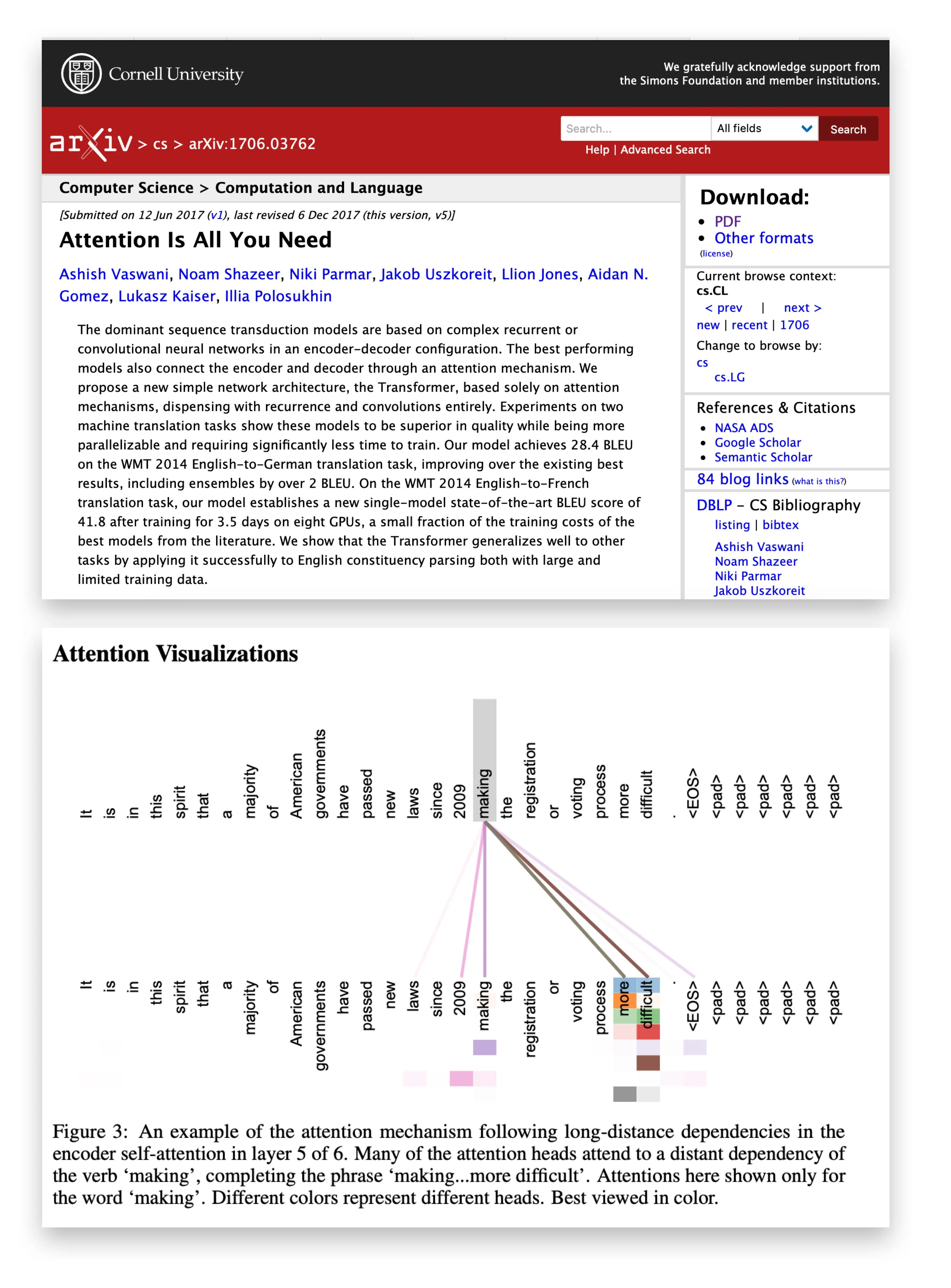
下图展示了真实模型中注意力权重的可视化——颜色越深表示注意力越强。可以看到 “making” 这个词主要关注 “more” 和 “difficult”,体现了语义依赖 1
五、FFN 子层:升维与降维#
先做 LayerNorm:
Y ~ ( l ) = L N ( Y ( l ) ) ∈ R B × T × d \tilde{Y}^{(l)} = \mathrm{LN}(Y^{(l)}) \in \mathbb{R}^{B \times T \times d} Y ~ ( l ) = LN ( Y ( l ) ) ∈ R B × T × d 5.1 第一层线性:升维#
W 1 ( l ) ∈ R d × d f f W_1^{(l)} \in \mathbb{R}^{d \times d_{ff}} W 1 ( l ) ∈ R d × d ff 对每个 token 位置 i i i
z i = y ~ i ⋅ W 1 ( l ) + b 1 z_i = \tilde{y}_i \cdot W_1^{(l)} + b_1 z i = y ~ i ⋅ W 1 ( l ) + b 1 写成矩阵形式:
Z = Y ~ ( l ) W 1 ( l ) + b 1 ∈ R B × T × d f f Z = \tilde{Y}^{(l)} W_1^{(l)} + b_1 \in \mathbb{R}^{B \times T \times d_{ff}} Z = Y ~ ( l ) W 1 ( l ) + b 1 ∈ R B × T × d ff 具体例子 :d = 768 , d f f = 3072 d = 768, d_{ff} = 3072 d = 768 , d ff = 3072
5.2 激活函数#
G = G E L U ( Z ) ∈ R B × T × d f f G = \mathrm{GELU}(Z) \in \mathbb{R}^{B \times T \times d_{ff}} G = GELU ( Z ) ∈ R B × T × d ff GELU 的公式(近似形式):
G E L U ( x ) = x ⋅ Φ ( x ) ≈ x ⋅ σ ( 1.702 x ) \mathrm{GELU}(x) = x \cdot \Phi(x) \approx x \cdot \sigma(1.702x) GELU ( x ) = x ⋅ Φ ( x ) ≈ x ⋅ σ ( 1.702 x ) 其中 Φ \Phi Φ
现代模型常用 SwiGLU 变体,引入门控机制:
S w i G L U ( x ) = S i L U ( x W a ) ⊙ ( x W b ) \mathrm{SwiGLU}(x) = \mathrm{SiLU}(x W_a) \odot (x W_b) SwiGLU ( x ) = SiLU ( x W a ) ⊙ ( x W b ) 其中 ⊙ \odot ⊙ W a , W b W_a, W_b W a , W b
5.3 第二层线性:降回 hidden size#
W 2 ( l ) ∈ R d f f × d W_2^{(l)} \in \mathbb{R}^{d_{ff} \times d} W 2 ( l ) ∈ R d ff × d O ffn = G ⋅ W 2 ( l ) + b 2 ∈ R B × T × d O_{\text{ffn}} = G \cdot W_2^{(l)} + b_2 \in \mathbb{R}^{B \times T \times d} O ffn = G ⋅ W 2 ( l ) + b 2 ∈ R B × T × d 5.4 残差连接#
X ( l + 1 ) = Y ( l ) + O ffn ∈ R B × T × d X^{(l+1)} = Y^{(l)} + O_{\text{ffn}} \in \mathbb{R}^{B \times T \times d} X ( l + 1 ) = Y ( l ) + O ffn ∈ R B × T × d 六、多层堆叠:维度不变,表示逐层演化#
X ( 0 ) → Block ( 0 ) X ( 1 ) → Block ( 1 ) X ( 2 ) → ⋯ X ( L ) X^{(0)} \xrightarrow{\text{Block}^{(0)}} X^{(1)} \xrightarrow{\text{Block}^{(1)}} X^{(2)} \xrightarrow{\cdots} X^{(L)} X ( 0 ) Block ( 0 ) X ( 1 ) Block ( 1 ) X ( 2 ) ⋯ X ( L ) 每一层输入输出都是 R B × T × d \mathbb{R}^{B \times T \times d} R B × T × d
紧凑写法:
X ( L ) = B l o c k ( L − 1 ) ∘ ⋯ ∘ B l o c k ( 0 ) ( X ( 0 ) ) X^{(L)} = \mathrm{Block}^{(L-1)} \circ \cdots \circ \mathrm{Block}^{(0)}(X^{(0)}) X ( L ) = Block ( L − 1 ) ∘ ⋯ ∘ Block ( 0 ) ( X ( 0 ) ) 每层结构相同,但参数独立 :
θ ( l ) = { W Q ( l ) , W K ( l ) , W V ( l ) , W O ( l ) , W 1 ( l ) , W 2 ( l ) , … } \theta^{(l)} = \{W_Q^{(l)}, W_K^{(l)}, W_V^{(l)}, W_O^{(l)}, W_1^{(l)}, W_2^{(l)}, \ldots\} θ ( l ) = { W Q ( l ) , W K ( l ) , W V ( l ) , W O ( l ) , W 1 ( l ) , W 2 ( l ) , … } 七、最后一层之后:从 hidden state 到 logits#
最后一层输出再做一次 LayerNorm:
H = L N ( X ( L ) ) ∈ R B × T × d H = \mathrm{LN}(X^{(L)}) \in \mathbb{R}^{B \times T \times d} H = LN ( X ( L ) ) ∈ R B × T × d 然后映射到词表空间:
W lm ∈ R d × V W_{\text{lm}} \in \mathbb{R}^{d \times V} W lm ∈ R d × V logits = H ⋅ W lm ∈ R B × T × V \text{logits} = H \cdot W_{\text{lm}} \in \mathbb{R}^{B \times T \times V} logits = H ⋅ W lm ∈ R B × T × V 每个 batch 样本、每个时间步,对词表中每个 token 都有一个预测分数。
八、残差的真正作用:增量叠加#
残差连接让每层学的是”增量修正”:
X ( l + 1 ) = X ( l ) + Δ ( l ) X^{(l+1)} = X^{(l)} + \Delta^{(l)} X ( l + 1 ) = X ( l ) + Δ ( l ) 这有三个关键效果:
梯度更容易传播 :反向传播时梯度可以沿残差连接直接流向浅层,不会被中间层的非线性”吃掉”原始信息不会丢 :底层编码的 token 身份、位置信息会被一路保留深层训练更稳定 :每层只需要学”补充什么”,而非”从零重造什么”
所以多层 Transformer 更像逐层加注释:
原始 token 身份 → + 局部依赖 → + 语义约束 → + 篇章关系 → + 任务特征 \text{原始 token 身份} \to +\text{局部依赖} \to +\text{语义约束} \to +\text{篇章关系} \to +\text{任务特征} 原始 token 身份 → + 局部依赖 → + 语义约束 → + 篇章关系 → + 任务特征 九、逐层抽象是怎么形成的#
单层 Attention 已经可以”看到全局”——每个 query 都会扫描所有历史 key。但**“看到全局”不等于”一步就提取出复杂抽象”**。
逐层抽象的形成机制:
第 l l l l l l 。这些 hidden state 已经经过了前面 l l l 所以第 1 层读到的是原始词向量附近的信息 ,第 8 层读到的是已带局部上下文的表示 ,第 22 层读到的是已经压入复杂组合关系的表示 。
每层的 FFN 再对 Attention 聚合后的结果做非线性重编码,把”混合信息”压成更适合表达高阶特征的方向。
所以常见的逐层特征演进是:
词级特征 → 短语关系 → 句子语义 → 跨句推理 \text{词级特征} \to \text{短语关系} \to \text{句子语义} \to \text{跨句推理} 词级特征 → 短语关系 → 句子语义 → 跨句推理 注意:这个过程的驱动力是 Attention 的反复聚合 + FFN 的非线性变换 ,残差只是保证这些新特征能在旧表示上稳定叠加。
十、三个最容易混淆的矩阵维度#
主干隐藏状态#
X ( l ) ∈ R B × T × d X^{(l)} \in \mathbb{R}^{B \times T \times d} X ( l ) ∈ R B × T × d 这是层与层之间真正传递的东西。
每头的 Q / K / V#
Q , K , V ∈ R B × H × T × d h Q, K, V \in \mathbb{R}^{B \times H \times T \times d_h} Q , K , V ∈ R B × H × T × d h Attention 内部临时展开的表示,不会传到下一层主干。
Attention 权重#
A ∈ R B × H × T × T A \in \mathbb{R}^{B \times H \times T \times T} A ∈ R B × H × T × T “每个位置看其他位置”的权重矩阵。这个矩阵同样不会传到下一层——下一层传的是 attention 输出加残差后的 X ( l + 1 ) X^{(l+1)} X ( l + 1 )
十一、具体数值例子#
取 B = 2 , T = 128 , d = 768 , H = 12 , d h = 64 , d f f = 3072 B=2,\; T=128,\; d=768,\; H=12,\; d_h=64,\; d_{ff}=3072 B = 2 , T = 128 , d = 768 , H = 12 , d h = 64 , d ff = 3072
步骤 Shape 层输入 X ( l ) X^{(l)} X ( l ) ( 2 , 128 , 768 ) (2, 128, 768) ( 2 , 128 , 768 ) Q / K / V 投影 ( 2 , 128 , 768 ) (2, 128, 768) ( 2 , 128 , 768 ) 拆头后 ( 2 , 12 , 128 , 64 ) (2, 12, 128, 64) ( 2 , 12 , 128 , 64 ) Attention score Q K ⊤ QK^\top Q K ⊤ ( 2 , 12 , 128 , 128 ) (2, 12, 128, 128) ( 2 , 12 , 128 , 128 ) 加权 V 后 ( 2 , 12 , 128 , 64 ) (2, 12, 128, 64) ( 2 , 12 , 128 , 64 ) 拼接回去 ( 2 , 128 , 768 ) (2, 128, 768) ( 2 , 128 , 768 ) 输出投影后 O attn O_{\text{attn}} O attn ( 2 , 128 , 768 ) (2, 128, 768) ( 2 , 128 , 768 ) 残差后 Y ( l ) Y^{(l)} Y ( l ) ( 2 , 128 , 768 ) (2, 128, 768) ( 2 , 128 , 768 ) FFN 第一层(升维) ( 2 , 128 , 3072 ) (2, 128, 3072) ( 2 , 128 , 3072 ) FFN 第二层(降回) ( 2 , 128 , 768 ) (2, 128, 768) ( 2 , 128 , 768 ) 层输出 X ( l + 1 ) X^{(l+1)} X ( l + 1 ) ( 2 , 128 , 768 ) (2, 128, 768) ( 2 , 128 , 768 )
层输入和层输出 shape 完全相同 ——这就是 Transformer 能任意堆叠的根本原因。
十二、总公式#
把整个模型压成最精简的形式:
X ( 0 ) = TokenEmb + PosEmb X^{(0)} = \text{TokenEmb} + \text{PosEmb} X ( 0 ) = TokenEmb + PosEmb 对 l = 0 , … , L − 1 l = 0, \ldots, L-1 l = 0 , … , L − 1
Q ( l ) , K ( l ) , V ( l ) = P r o j ( L N ( X ( l ) ) ) Q^{(l)}, K^{(l)}, V^{(l)} = \mathrm{Proj}(\mathrm{LN}(X^{(l)})) Q ( l ) , K ( l ) , V ( l ) = Proj ( LN ( X ( l ) )) A t t n ( l ) = s o f t m a x ( Q ( l ) ( K ( l ) ) ⊤ d h + M ) V ( l ) \mathrm{Attn}^{(l)} = \mathrm{softmax}\!\left(\frac{Q^{(l)} (K^{(l)})^\top}{\sqrt{d_h}} + M\right) V^{(l)} Attn ( l ) = softmax ( d h Q ( l ) ( K ( l ) ) ⊤ + M ) V ( l ) Y ( l ) = X ( l ) + O u t P r o j ( A t t n ( l ) ) Y^{(l)} = X^{(l)} + \mathrm{OutProj}(\mathrm{Attn}^{(l)}) Y ( l ) = X ( l ) + OutProj ( Attn ( l ) ) X ( l + 1 ) = Y ( l ) + F F N ( L N ( Y ( l ) ) ) X^{(l+1)} = Y^{(l)} + \mathrm{FFN}(\mathrm{LN}(Y^{(l)})) X ( l + 1 ) = Y ( l ) + FFN ( LN ( Y ( l ) )) 最终:
logits = L N ( X ( L ) ) ⋅ W lm ∈ R B × T × V \text{logits} = \mathrm{LN}(X^{(L)}) \cdot W_{\text{lm}} \in \mathbb{R}^{B \times T \times V} logits = LN ( X ( L ) ) ⋅ W lm ∈ R B × T × V 四行核心公式,描述了从输入到输出的完整计算过程。主干张量始终是 ( B , T , d ) (B, T, d) ( B , T , d ) ( B , H , T , d h ) (B, H, T, d_h) ( B , H , T , d h ) ( B , T , d f f ) (B, T, d_{ff}) ( B , T , d ff ) ( B , T , d ) (B, T, d) ( B , T , d )
附录 A:Cross-Attention#
在 encoder-decoder 架构(如原始 Transformer 1 cross-attention 子层。
与 self-attention 的区别只有一点:Q 来自 decoder,K/V 来自 encoder:
Q = X dec W Q , K = X enc W K , V = X enc W V Q = X_{\text{dec}} W_Q, \quad K = X_{\text{enc}} W_K, \quad V = X_{\text{enc}} W_V Q = X dec W Q , K = X enc W K , V = X enc W V CrossAttn ( Q , K , V ) = s o f t m a x ( Q K ⊤ d h ) V \text{CrossAttn}(Q, K, V) = \mathrm{softmax}\!\left(\frac{Q K^\top}{\sqrt{d_h}}\right) V CrossAttn ( Q , K , V ) = softmax ( d h Q K ⊤ ) V 也就是说,decoder 用自己当前的状态去”查询” encoder 的输出。维度流与 self-attention 完全一致,只是 Q 和 K/V 来自不同序列 2
在 decoder-only 模型(GPT、LLaMA 等)中不存在 cross-attention,所有 attention 都是 self-attention。